История про хранилище изображений. Или как велосипед спас от костыля
На днях мы порелизили новую фичу — Дорожные события в навигаторе. Теперь пользователи мобильных приложений могут не только посмотреть на дорожные пробки и места расположения скоростных камер, но и участвовать в обмене информацией на дорогах: указать места ДТП, дорожных работ, перекрытий, а также просто пообщаться. Помимо указанных мест сориентироваться в ситуации помогут добавленные фотографии.
В статье расскажу, как мы разработали сервис, способный хранить миллионы фотографий и обслуживать тысячи запросов в секунду.
В 2ГИС очень много внимания уделяется контенту и его качеству. Один из типов контента — изображения. Перед нами часто возникают задачи:
Сервисов у нас прилично. И каждый раз всё делать заново и наступать на одни и те же грабли нам не хочется.
В один прекрасный солнечный день во время планирования к нам поступила очередная задача: в приложениях скоро появятся дорожные события. Помимо того, что их смогут создавать пользователи, к ним можно будет прикреплять фотографии, чтобы предоставить пользователям больше информации о ситуации на дорогах.
На тот момент ситуация с добавлением пользовательских фоточек в продукт подразумевала два варианта:

Выбор дался нам довольно тяжело: интеграция с сервисом Photo добавляла дополнительных неудобств всем участникам взаимодействия, а путь прямой интеграция с хранилищем — ещё один велосипед в рамках каждого сервиса. Кроме того, потребность в поддержке работы с изображениями была не только у Дорожных событий, но и ещё у нескольких фич.
Поэтому мы пошли другим путём — выделили специализированный сервис FileKeeper, который помимо базовых операций над изображениями:
Нужно отметить, что большую часть всех требований и решений удалось довольно быстро сформулировать благодаря опыту, полученному в ходе эксплуатации сервиса Photo.
Концептуальная схема нового сервиса, а точнее — группы сервисов:
На схеме изображены следующие элементы:
Архитектура понятна. Теперь стоит рассказать о том, как сервис можно использовать. Интеграция основана на следующих правилах:
Соблюдение таких правил упрощает реализацию, а также позволяет гибко управлять подключением новых провайдеров, предоставляя возможности задавать ограничения на свои данные и даже выбирать способ хранения.
Может показаться несколько странным, что загрузка файлов проходит через провайдер — дополнительное лишнее звено.
Причины такого решения:
Рассматривать все сценарии взаимодействия между провайдером и API довольно скучно. Наиболее интересный для разбора — загрузка изображений. Именно на нём и остановимся подробнее.
На входе имеем: ключ, выданный провайдеру для взаимодействия с FileKeeper API, набор изображений для загрузки и знание спейса, в который хотим положить все изображения.
Позитивный сценарий:
И всё было было бы хорошо, если бы все сценарии были позитивными, но…
Что-то может пойти не так?
Любая интеграция между разными приложениями приводит к большому количеству нюансов и мест для удара головой: недоступность сервиса, сетевые задержки, разрывы соединений, заканчивающееся место на диске, приход OOM-киллера.
Большую часть всех проблем можно разбить на группы, которые как раз соответствуют каналу взаимодействия совместно с «сервисом-приёмником». Рассмотрим их по порядку.
Отказ FileKeeper API (1) может возникнуть вследствие недоступности сервиса, таймаута подключения или ошибки при разборке и проверке корректности запроса.
Отказ может быть чреват только тем, что запрос будет отвергнут на старте обработки и провайдеру придётся его обработать.
Отказ PG HA (2) может возникнуть из-за некорректного sql-запроса, нарушения ограничений целостности, установленных на уровне БД, разрыва или сетевых проблем.
В данном случае обработать ошибку должен не только провайдер, но и сервис FileKeeper API.
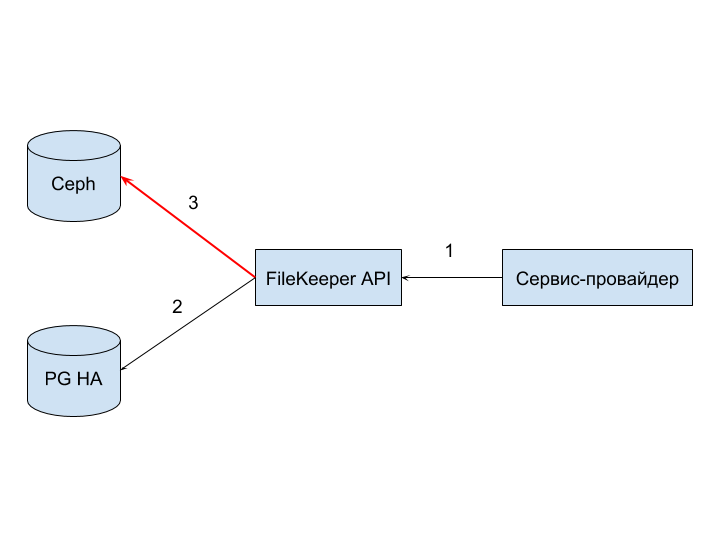
Отказ Ceph (3) может возникнуть как из-за сетевых проблем, аналогично предыдущим вариантам отказов, так и из-за отказа в обслуживании по причине некорректности ключей доступа, отсутствия доступного места, недостаточности прав для записи.
Отказ более проблемный, нежели предыдущие два, так как в PG HA уже есть запись о файле, а привести её в активное состояние не получилось — так появился «зомбированный» файл. Это как раз тот случай, когда нужно и ошибку обработать, и данные почистить. Чистка мусора после таких проблем — одна из задач Recycler.
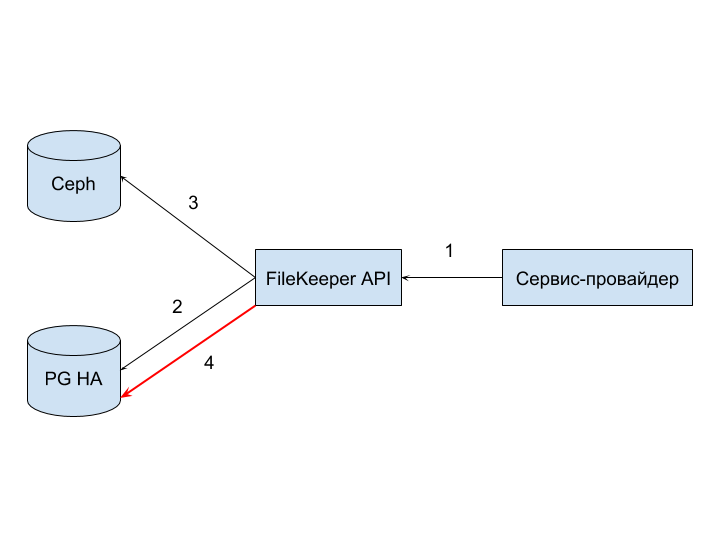
Причины отказа PG HA (4) аналогичны (2), последствия и их разрешение подобны (3).
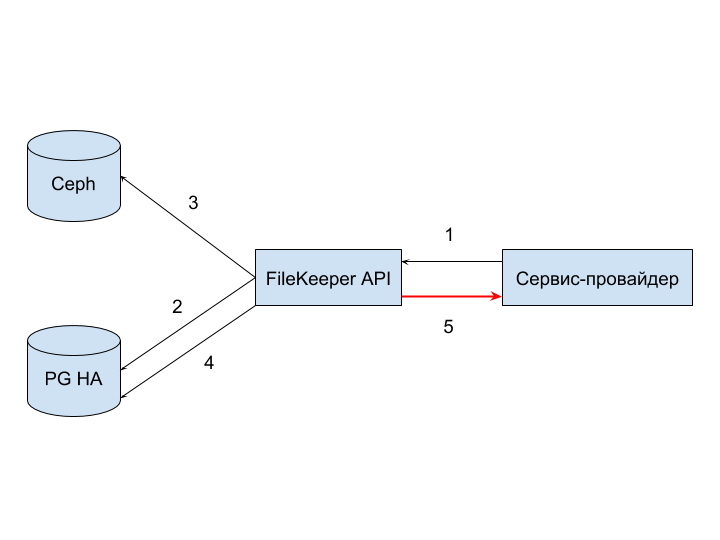
Существует ещё один вид — отказ провайдера принимать ответ (5). Произойти он может по причине срабатывания таймаута на обработку запроса на стороне провайдера.
Такие отказы тяжело системно обрабатывать, так как разрыв соединения находится вне контроля сервиса. Ликвидация корректно обработанных запросов, которые не дошли до инициатора, может осуществляться через мониторинг, а также путём периодической сверки хранимых файлов и файлов, о которых знает провайдер.
Релиз Дорожных событий прошёл успешно. Теперь самое время подумать о том, чего удалось достигнуть и куда двигаться дальше.
Помимо очевидного, реализовав FileKeeper мы:
В статье расскажу, как мы разработали сервис, способный хранить миллионы фотографий и обслуживать тысячи запросов в секунду.
Куда мы шагнули?
В 2ГИС очень много внимания уделяется контенту и его качеству. Один из типов контента — изображения. Перед нами часто возникают задачи:
- принимать и хранить фото пользователей (как внутренних, так и внешних),
- генерировать превью разных размеров,
- быстро раздавать сохранённые данные и метаинформацию о них.
Сервисов у нас прилично. И каждый раз всё делать заново и наступать на одни и те же грабли нам не хочется.
В один прекрасный солнечный день во время планирования к нам поступила очередная задача: в приложениях скоро появятся дорожные события. Помимо того, что их смогут создавать пользователи, к ним можно будет прикреплять фотографии, чтобы предоставить пользователям больше информации о ситуации на дорогах.
На тот момент ситуация с добавлением пользовательских фоточек в продукт подразумевала два варианта:
- Интеграция с существующим сервисом Photo (хранит фото фирм и геообъектов). Назвать вариант удобным очень непросто:
- Бизнес-логика заточена под конкретные сценарии работы с фото объектов справочного API.
- В схеме загрузки фото много звеньев: загрузка в несколько запросов + пересылки бинарников между дата-центрами.
- Большое количество клиентов, изменение форматов работы с которыми просто невозможно. А обратную совместимость мы не ломаем.
- Интеграция с Ceph (объектное хранилище с поддержкой S3) без посредников также не выглядит очень радужно:
- Преобразования и валидацию изображений при загрузке нужно реализовывать в каждом сервисе.
- Доступность в нескольких дата-центрах ресайзеров и CDN нужно организовывать отдельно, либо встраивать в существующее решение от Photo, которое неудобно отлаживать.
- От реализации к реализации ошибки будут повторяться.
Какой путь реализации выбрали
Выбор дался нам довольно тяжело: интеграция с сервисом Photo добавляла дополнительных неудобств всем участникам взаимодействия, а путь прямой интеграция с хранилищем — ещё один велосипед в рамках каждого сервиса. Кроме того, потребность в поддержке работы с изображениями была не только у Дорожных событий, но и ещё у нескольких фич.
Поэтому мы пошли другим путём — выделили специализированный сервис FileKeeper, который помимо базовых операций над изображениями:
- не будет завязан на доменные модели данных интегрированных сервисов, ограничиваясь группировкой хранимых данных по источнику (каждую такую группу мы называем «space»),
- инкапсулирует знания о логике хранения изображений,
- просто масштабируется и готов к высоким нагрузкам (ориентируемся на возможность достичь нескольких тысяч RPS при необходимости).
Нужно отметить, что большую часть всех требований и решений удалось довольно быстро сформулировать благодаря опыту, полученному в ходе эксплуатации сервиса Photo.
Архитектура
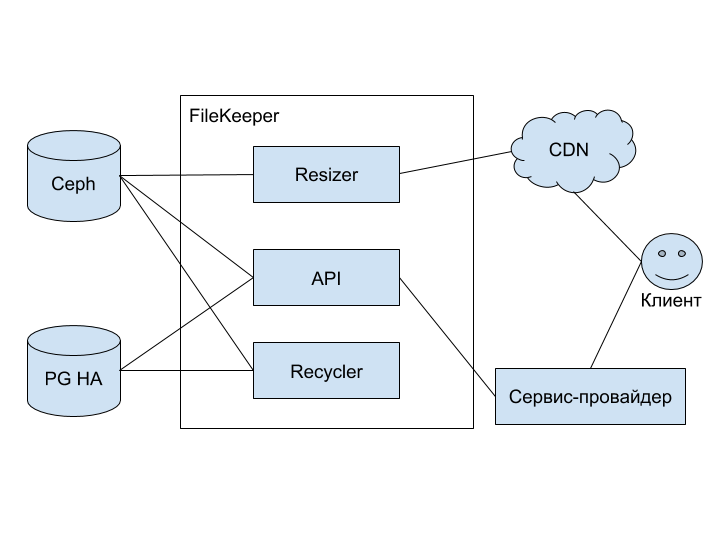
Концептуальная схема нового сервиса, а точнее — группы сервисов:
На схеме изображены следующие элементы:
- Ceph — объектное хранилище с поддержкой протокола S3 (подробно можно почитать здесь),
- PG HA — высокодоступный кластер на основе PostgreSQL,
- FileKeeper — группа сервисов для хранения и работы с изображениями,
- Resizer — сервис-преобразователь изображений; основной тип преобразования — изменение размера,
- API — сервис, предоставляющий REST-интерфейс для управления хранимыми изображениями,
- Recycler — сервис, отвечающий за чистку старых файлов и зомбированных файлов (о способе их появления расскажу ниже),
- Сервис-провайдер — мастер-сервис, который использует FileKeeper для хранения изображений, связанных с собственными данными,
- CDN — сеть доставки изображений и их преобразованных копий ближе к клиенту,
- Клиент — приложение, с которым взаимодействует конечный пользователь (web- или мобильная версия 2ГИС).
Интеграция
Архитектура понятна. Теперь стоит рассказать о том, как сервис можно использовать. Интеграция основана на следующих правилах:
- доступ к работе с API осуществляется по авторизационному ключу,
- все ограничения и операции осуществляются в рамках спейса,
- провайдер является как инициатором загрузки файла, так и инициатором его удаления,
- интеграции возможны только на уровне сервис — сервис.
Соблюдение таких правил упрощает реализацию, а также позволяет гибко управлять подключением новых провайдеров, предоставляя возможности задавать ограничения на свои данные и даже выбирать способ хранения.
Может показаться несколько странным, что загрузка файлов проходит через провайдер — дополнительное лишнее звено.
Причины такого решения:
- Без провайдера никак. Провайдер, как мастер-система, так или иначе должен участвовать во взаимодействии. Иначе он не узнает о файле, относящемся к его данным.
- Контроль и безопасность. Для загрузки с клиента нужно предусматривать особый способ авторизации, чтобы не допустить использование сервиса в качестве файлопомойки.
- Время. Мы намеренно не стали усложнять задачу и реализовывать сложные сценарии, чтобы минимально влиять на сроки релиза Дорожных событий.
Загрузка файлов
Рассматривать все сценарии взаимодействия между провайдером и API довольно скучно. Наиболее интересный для разбора — загрузка изображений. Именно на нём и остановимся подробнее.
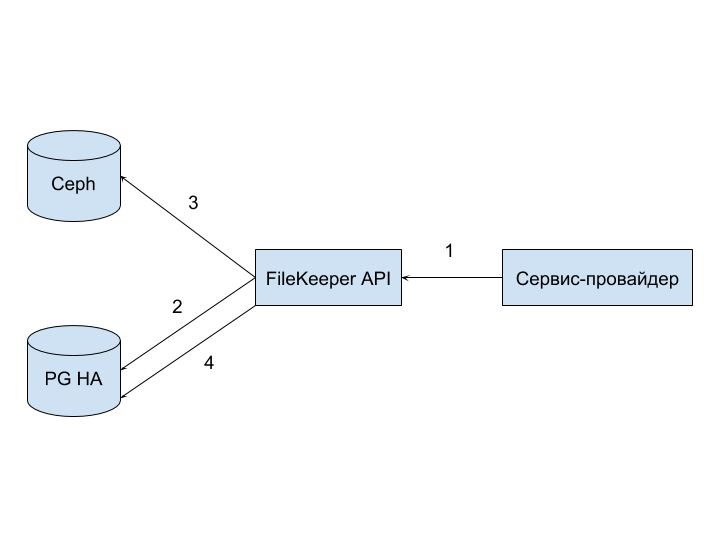
На входе имеем: ключ, выданный провайдеру для взаимодействия с FileKeeper API, набор изображений для загрузки и знание спейса, в который хотим положить все изображения.
Позитивный сценарий:
- Upload: провайдер отправляет запрос в API.
- Prepare: API предварительно сохраняет метаинформацию файлов и текущую дату в PG HA c пометкой о том, что «файл подготовлен».
- Store: сохранение самих изображений в Ceph.
- Ready: Public API помечает все файлы флагом «файл загружен» в PG HA.
И всё было было бы хорошо, если бы все сценарии были позитивными, но…
Что-то может пойти не так?
Любая интеграция между разными приложениями приводит к большому количеству нюансов и мест для удара головой: недоступность сервиса, сетевые задержки, разрывы соединений, заканчивающееся место на диске, приход OOM-киллера.
Большую часть всех проблем можно разбить на группы, которые как раз соответствуют каналу взаимодействия совместно с «сервисом-приёмником». Рассмотрим их по порядку.
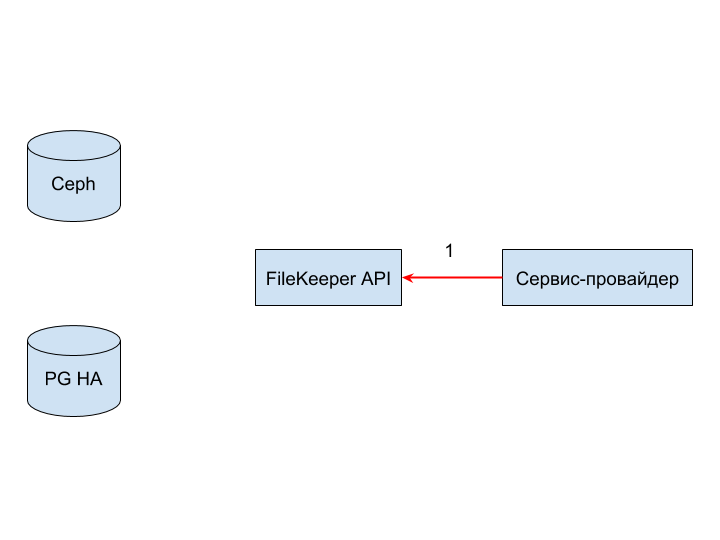
Отказ FileKeeper API (1) может возникнуть вследствие недоступности сервиса, таймаута подключения или ошибки при разборке и проверке корректности запроса.
Отказ может быть чреват только тем, что запрос будет отвергнут на старте обработки и провайдеру придётся его обработать.
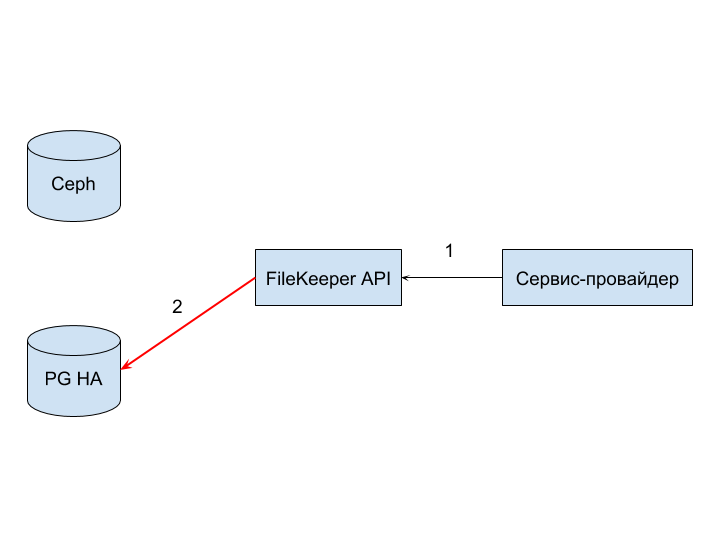
Отказ PG HA (2) может возникнуть из-за некорректного sql-запроса, нарушения ограничений целостности, установленных на уровне БД, разрыва или сетевых проблем.
В данном случае обработать ошибку должен не только провайдер, но и сервис FileKeeper API.
Отказ Ceph (3) может возникнуть как из-за сетевых проблем, аналогично предыдущим вариантам отказов, так и из-за отказа в обслуживании по причине некорректности ключей доступа, отсутствия доступного места, недостаточности прав для записи.
Отказ более проблемный, нежели предыдущие два, так как в PG HA уже есть запись о файле, а привести её в активное состояние не получилось — так появился «зомбированный» файл. Это как раз тот случай, когда нужно и ошибку обработать, и данные почистить. Чистка мусора после таких проблем — одна из задач Recycler.
Причины отказа PG HA (4) аналогичны (2), последствия и их разрешение подобны (3).
Существует ещё один вид — отказ провайдера принимать ответ (5). Произойти он может по причине срабатывания таймаута на обработку запроса на стороне провайдера.
Такие отказы тяжело системно обрабатывать, так как разрыв соединения находится вне контроля сервиса. Ликвидация корректно обработанных запросов, которые не дошли до инициатора, может осуществляться через мониторинг, а также путём периодической сверки хранимых файлов и файлов, о которых знает провайдер.
Результаты
Релиз Дорожных событий прошёл успешно. Теперь самое время подумать о том, чего удалось достигнуть и куда двигаться дальше.
Помимо очевидного, реализовав FileKeeper мы:
- Выделили востребованную часть функционала в отдельный сервис, то есть не усложнили поддержку существующего продукта.
- Ещё раз осознали важность наличия и своевременности нагрузочного тестирования в разработке. Преобразование изображений довольно дорогая операция, требующая приличного объёма оперативной памяти и процессорного времени. Первая реализация показала себя не очень хорошо под нагрузкой, быстро съедая гигабайты памяти и умирая от удара OOM-киллера, что отсрочило дату релиза.
- Получили гибкую реализацию сервиса хранения файлов, готовую к обслуживанию разных провайдеров с разными потребностями: один провайдер уже есть, второй на подходе. При этом для разных провайдеров могут использоваться различные хранилища бинарных и метаданных в зависимости от потребностей доступности и скорости чтения и записи в разных ДЦ.
Немного советов от капитана
- Не всегда стоит пытаться встроить новую фичу в существующее решение. Если встраивание выглядит как костыль, стоит остановиться и задуматься: а может настал момент выделить востребованный функционал в отдельный сервис? Нам такая остановка помогла. Возможно, поможет и вам.
- Распределенные системы по сравнению с монолитами сложны тем, что можно поймать очень много проблем при межсетевом взаимодействии — не забывайте предусматривать обработку негативных сценариев.
- С вашим сервисом взаимодействуют другие сервисы — система мониторинга должна быть готова разделять источники запросов. Если вы видите, что нагрузка на сервис неожиданно сильно повысилась, но не можете вычислить виновника, то и повлиять на ситуацию вряд ли получится.
- Не пытайтесь построить сервис преобразования изображений, основываясь на подходе преобразований на лету на каждый запрос. Без кэширования сервис обречён на огромные затраты системных ресурсов. Кэширование должно быть предсказуемым и управляемым — это пойдёт на пользу как в процессе отладки и тестирования, так и на случай письма от Роскомнадзора.
- Решили обрабатывать изображения под нагрузкой — проведите нагрузочное тестирование на прототипе. В процессе тестирования есть вероятность сменить не одну библиотеку для обработки изображений. Мы сменили не одну из-за прожорливости по отношению к оперативной памяти.
- 33832 reads
Who's online
There are currently 1 user and 5 guests online.
Copyright © Home Co. Ltd. LLC, 2008-2022 - Kurgan-Telecom.Ru - VDS/VPS Хостинг в Кургане - All Rights Reserved

