Замедляем Windows, часть 2: создание процессов
Windows давно упрекают за медлительность файловых операций и создания процессов. А вы когда-нибудь пробовали сделать их ещё медленнее? Эта статья покажет технику, как постепенно замедлять создание процессов в Windows (до бесконечности) незаметно для большинства пользователей!
И конечно, статья также расскажет, как обнаружить и избежать этой проблемы.
Это реальная проблема, с которой я столкнулся в начале года, и статья объясняет, как я её обнаружил и нашёл обходной путь. Предыдущие статьи о замедлении Windows:
Я не ищу неприятностей, но, кажется, я их нашел. Может, потому что собираю Chrome из исходников сотни раз за выходные или я по жизни невезуч. Думаю, мы никогда не узнаем. Так или иначе, эта статья описывает пятую серьёзную проблему, с которой я столкнулся в Windows при сборке Chrome.
Компьютеры должны быть надёжными и предсказуемыми, и меня раздражает иное. Если я собираю Chrome несколько сотен раз подряд, хотелось бы видеть успешной каждую сборку. Поэтому когда наш распределённый процесс компиляции (gomacc.exe) иногда вылетает — я хочу это исследовать. У меня настроена автоматическая запись аварийных дампов, поэтому я вижу, что сбои происходят при обнаружении повреждения кучи. Простой способ проверить — включить pageheap, чтобы куча Windows помещала каждое выделение памяти на отдельную страницу. Это означает, что use-after-free и переполнения буфера приводят к мгновенному сбою вместо трудно диагностируемого повреждения. Я уже ранее писал о включении pageheap с помощью App Verifier.
App Verifier приводит к замедлению работы программы по двум причинам: выделения памяти замедляются, а выровненные по страницам выделения практически дезактивируют кэш процессора. Таким образом, небольшое замедление сборки было предсказуемо, так и произошло.
Но когда я зашёл позже, сборка как будто вообще остановилась. После примерно 7000 шагов сборки не было заметно никакого прогресса.
Оказывается, Application Verifier любит создавать файлы журналов. И неважно, что никто не смотрит эти файлы, он создаёт их на всякий случай. И у этих файлов должны быть уникальные имена. Я уверен, что казалось хорошей идеей просто дать логам численные названия в возрастающем порядке, такие как gomacc.exe.0.dat, gomacc.exe.1.dat и так далее.
Чтобы получить численные названия в возрастающем порядке, нужно определить, какое число использовать следующим. Самый простой способ — попробовать возможные имена/числа, пока не найдёте то, которое ещё не использовалось. То есть попробовать создать новый файл с названием gomacc.exe.0.dat, а если он уже существует, попробовать gomacc.exe.1.dat и так далее.
Что может пойти не так?
Оказывается, если выполнять линейный поиск неиспользуемого имени файла при создании процесса, то запуск N процессов занимает O(N^2) операций. Здравый смысл подсказывает, что алгоритмы O(N^2) слишком медленные, если вы не можете гарантировать, что N всегда остаётся относительно малым.
Насколько именно плохой станет ситуация — зависит от того, сколько времени занимает проверка существования файла. Я провёл измерения и обнаружил, что в Windows она занимает около 80 микросекунд (80 мкс или 0,08 мс). Запуск первого процесса происходит быстро, но запуск 1000-го процесса требует сканирования 1000 уже созданных файлов журнала. Это занимает 80 мс, а затем ещё больше.
Типичная сборка Chrome требует запуска компилятора около 30 000 раз. Каждый запуск компилятора требует сканирования N ранее созданных файлов журнала, по 0,08 мс для проверки каждого файла. Линейный поиск следующего доступного имени файла журнала означает, что для запуска N процессов требуется (N^2)/2 проверок существования файла, то есть 30,000 * 30,000 / 2, что составляет 450 миллионов. Поскольку каждая проверка существования файла занимает 0,08 мс, это 36 миллионов миллисекунд, или 36 000 секунд. То есть время сборки Chrome, которое обычно составляет от пяти до десяти минут, увеличится ещё на десять часов.
Блин.
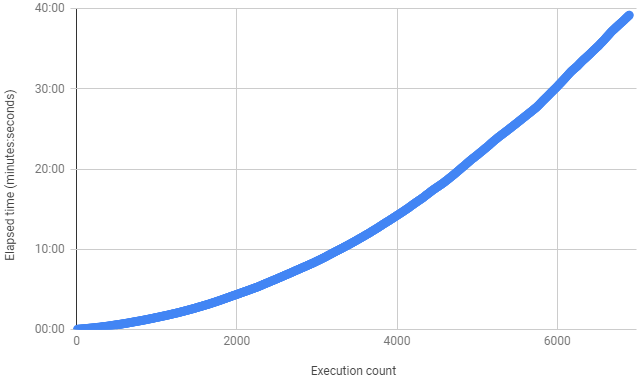
При написании этой статьи я воспроизвёл ошибку, запустив пустой исполняемый файл около 7000 раз — и увидел чёткую кривую O(n^2) вроде такой:
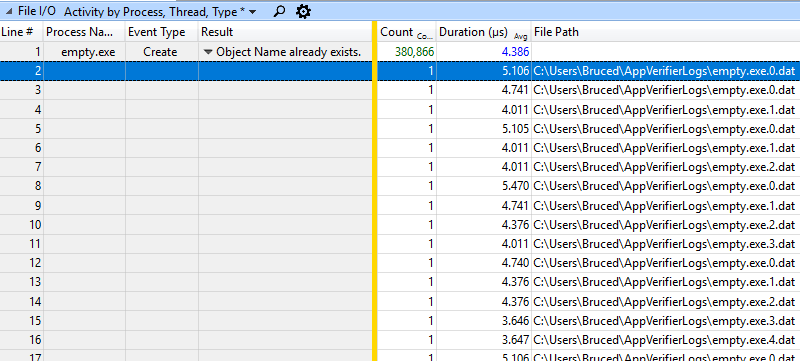
Как ни странно, если взять трассировку ETW и посмотреть на среднее время вызова CreateFile, то почти для всех файлов показан результат менее пяти микросекунд (в среднем 4,386 мкс в примере ниже):
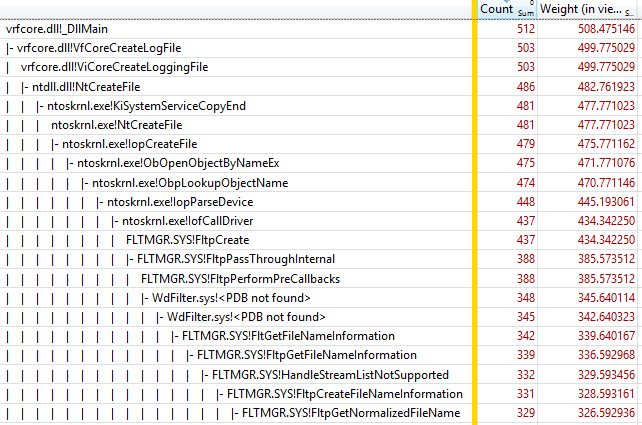
Похоже, что здесь показано просто ограничение ETW на трассировку ввода-вывода файла. События файлового ввода-вывода отслеживают только самый низкий уровень файловой системы, а выше Ntfs.sys есть ещё много уровней, включая FLTMGR.SYS и ntoskrnl.exe. Однако подтормаживание невозможно полностью скрыть — использование CPU видно на графике CPU Usage. На скриншоте ниже показан временной интервал 548 мс, представляющий собой создание одного процесса. В основном, всё время тратится только на сканирование около 6850 возможных имён файлов лога:
Нет.
Объём обрабатываемых данных невелик, а объём записи на диск ещё меньше. Во время моих тестов для воспроизведения бага диск почти полностью простаивал. Это проблема связана с CPU, поскольку все соответствующие данные диска кэшируются. И даже если бы накладные расходы сократились на порядок, они всё равно были бы слишком большими. Вы не можете улучшить алгоритм O(N^2).
Эту конкретную проблему можно обнаружить, выполнив поиск в %userprofile%\appverifierlogs на предмет файлов .dat. В целом можно обнаружить замедление создания процессов, изучив трассировку ETW, и теперь вы знаете, что искать.
Самое простое решение — отключить журналирование. Это также остановит заполнение диска гигабайтами логов. Оно отключается следующей командой:
После отключения журналирования я обнаружил, что мои процессы стартовали примерно в три раза быстрее (!), чем в начале теста, а замедление полностью исчезло. 7000 отслеживаемых процессов Application Verifier создаются за 1,5 минуты, а не за 40 минут. С моим простым пакетным файлом для тестов и простым процессом я вижу такие скорости создания процессов:
Microsoft может исправить эту проблему, отказавшись от монотонного увеличения номеров лог-файлов. Если бы в качестве имени файла они использовали текущую дату и время (до миллисекунды или в более высоком разрешении), то получили бы более семантически значимые названия логов, которые создаются очень быстро практически без логики поиска уникального файла.
Но Application Verifier больше не поддерживается, а файлы журналов всё равно бесполезны, поэтому просто отключите их.
Пакетные файлы и скрипт для воссоздания бага после включения Application Verifier для empty.exe можно найти здесь.
Трассировка ETW примерно с конца эксперимента — здесь.
Другие ссылки:
Необработанные данные по таймингу, используемые для создания графика
Обсуждение на Reddit
Обсуждение на Hacker News
Примеры других алгоритмов O(n^2), которые идут вразнос, см. на Accidentally Quadratic
Для более приземлённого удовольствия см. видеоподборку моих 19 разных способов добраться на работу в сентябре — я был слишком занят, чтобы продолжать эксперимент в этом месяце.
И конечно, статья также расскажет, как обнаружить и избежать этой проблемы.
Это реальная проблема, с которой я столкнулся в начале года, и статья объясняет, как я её обнаружил и нашёл обходной путь. Предыдущие статьи о замедлении Windows:
- Замедляем Windows, часть 0: произвольное замедление VirtualAlloc
- Замедляем Windows, часть 1: файловый доступ
Что-то не так
Я не ищу неприятностей, но, кажется, я их нашел. Может, потому что собираю Chrome из исходников сотни раз за выходные или я по жизни невезуч. Думаю, мы никогда не узнаем. Так или иначе, эта статья описывает пятую серьёзную проблему, с которой я столкнулся в Windows при сборке Chrome.
- Незапланированная сериализация, которая приводит к полноценному зависанию UI: «24-ядерный процессор, а я не могу сдвинуть курсор».
- Утечка дескриптора процесса в одном из дополнений Microsoft для Windows: «Зомби-процессы съедают вашу память».
- Давняя ошибка корректности в файловом кэше Windows: «Ошибка компилятора? Ошибка компоновщика? Баг ядра Windows».
- Сбой производительности при неправильном использовании уведомлений о файлах: «Замедляем Windows, часть 1: файловый доступ».
- И эта: странное архитектурное решение, которое со временем замедляет создание процессов.
Отслеживание редкого сбоя
Компьютеры должны быть надёжными и предсказуемыми, и меня раздражает иное. Если я собираю Chrome несколько сотен раз подряд, хотелось бы видеть успешной каждую сборку. Поэтому когда наш распределённый процесс компиляции (gomacc.exe) иногда вылетает — я хочу это исследовать. У меня настроена автоматическая запись аварийных дампов, поэтому я вижу, что сбои происходят при обнаружении повреждения кучи. Простой способ проверить — включить pageheap, чтобы куча Windows помещала каждое выделение памяти на отдельную страницу. Это означает, что use-after-free и переполнения буфера приводят к мгновенному сбою вместо трудно диагностируемого повреждения. Я уже ранее писал о включении pageheap с помощью App Verifier.
App Verifier приводит к замедлению работы программы по двум причинам: выделения памяти замедляются, а выровненные по страницам выделения практически дезактивируют кэш процессора. Таким образом, небольшое замедление сборки было предсказуемо, так и произошло.
Но когда я зашёл позже, сборка как будто вообще остановилась. После примерно 7000 шагов сборки не было заметно никакого прогресса.
O(n^2) — это обычно не к добру
Оказывается, Application Verifier любит создавать файлы журналов. И неважно, что никто не смотрит эти файлы, он создаёт их на всякий случай. И у этих файлов должны быть уникальные имена. Я уверен, что казалось хорошей идеей просто дать логам численные названия в возрастающем порядке, такие как gomacc.exe.0.dat, gomacc.exe.1.dat и так далее.
Чтобы получить численные названия в возрастающем порядке, нужно определить, какое число использовать следующим. Самый простой способ — попробовать возможные имена/числа, пока не найдёте то, которое ещё не использовалось. То есть попробовать создать новый файл с названием gomacc.exe.0.dat, а если он уже существует, попробовать gomacc.exe.1.dat и так далее.
Что может пойти не так?
На самом деле, в худшем случае всё довольно плохо
Оказывается, если выполнять линейный поиск неиспользуемого имени файла при создании процесса, то запуск N процессов занимает O(N^2) операций. Здравый смысл подсказывает, что алгоритмы O(N^2) слишком медленные, если вы не можете гарантировать, что N всегда остаётся относительно малым.
Насколько именно плохой станет ситуация — зависит от того, сколько времени занимает проверка существования файла. Я провёл измерения и обнаружил, что в Windows она занимает около 80 микросекунд (80 мкс или 0,08 мс). Запуск первого процесса происходит быстро, но запуск 1000-го процесса требует сканирования 1000 уже созданных файлов журнала. Это занимает 80 мс, а затем ещё больше.
Типичная сборка Chrome требует запуска компилятора около 30 000 раз. Каждый запуск компилятора требует сканирования N ранее созданных файлов журнала, по 0,08 мс для проверки каждого файла. Линейный поиск следующего доступного имени файла журнала означает, что для запуска N процессов требуется (N^2)/2 проверок существования файла, то есть 30,000 * 30,000 / 2, что составляет 450 миллионов. Поскольку каждая проверка существования файла занимает 0,08 мс, это 36 миллионов миллисекунд, или 36 000 секунд. То есть время сборки Chrome, которое обычно составляет от пяти до десяти минут, увеличится ещё на десять часов.
Блин.
При написании этой статьи я воспроизвёл ошибку, запустив пустой исполняемый файл около 7000 раз — и увидел чёткую кривую O(n^2) вроде такой:
Как ни странно, если взять трассировку ETW и посмотреть на среднее время вызова CreateFile, то почти для всех файлов показан результат менее пяти микросекунд (в среднем 4,386 мкс в примере ниже):
Похоже, что здесь показано просто ограничение ETW на трассировку ввода-вывода файла. События файлового ввода-вывода отслеживают только самый низкий уровень файловой системы, а выше Ntfs.sys есть ещё много уровней, включая FLTMGR.SYS и ntoskrnl.exe. Однако подтормаживание невозможно полностью скрыть — использование CPU видно на графике CPU Usage. На скриншоте ниже показан временной интервал 548 мс, представляющий собой создание одного процесса. В основном, всё время тратится только на сканирование около 6850 возможных имён файлов лога:
Поможет ли более производительный диск?
Нет.
Объём обрабатываемых данных невелик, а объём записи на диск ещё меньше. Во время моих тестов для воспроизведения бага диск почти полностью простаивал. Это проблема связана с CPU, поскольку все соответствующие данные диска кэшируются. И даже если бы накладные расходы сократились на порядок, они всё равно были бы слишком большими. Вы не можете улучшить алгоритм O(N^2).
Обнаружение
Эту конкретную проблему можно обнаружить, выполнив поиск в %userprofile%\appverifierlogs на предмет файлов .dat. В целом можно обнаружить замедление создания процессов, изучив трассировку ETW, и теперь вы знаете, что искать.
Решение
Самое простое решение — отключить журналирование. Это также остановит заполнение диска гигабайтами логов. Оно отключается следующей командой:
appverif.exe -logtofile disableПосле отключения журналирования я обнаружил, что мои процессы стартовали примерно в три раза быстрее (!), чем в начале теста, а замедление полностью исчезло. 7000 отслеживаемых процессов Application Verifier создаются за 1,5 минуты, а не за 40 минут. С моим простым пакетным файлом для тестов и простым процессом я вижу такие скорости создания процессов:
- обычно 200 в секунду (5 мс на процесс)
- 75 в секунду при включенном Application Verifier, но отключенным ведением логов (13 мс на процесс)
- 40 в секунду с включенным Application Verifier и включенным журналированием, поначалу… (25 мс на процесс, время постепенно увеличивается до бесконечности)
- 0,4 в секунду после одной сборки Chrome
Microsoft может исправить эту проблему, отказавшись от монотонного увеличения номеров лог-файлов. Если бы в качестве имени файла они использовали текущую дату и время (до миллисекунды или в более высоком разрешении), то получили бы более семантически значимые названия логов, которые создаются очень быстро практически без логики поиска уникального файла.
Но Application Verifier больше не поддерживается, а файлы журналов всё равно бесполезны, поэтому просто отключите их.
Вспомогательная информация
Пакетные файлы и скрипт для воссоздания бага после включения Application Verifier для empty.exe можно найти здесь.
Трассировка ETW примерно с конца эксперимента — здесь.
Другие ссылки:
Необработанные данные по таймингу, используемые для создания графика
Обсуждение на Reddit
Обсуждение на Hacker News
Примеры других алгоритмов O(n^2), которые идут вразнос, см. на Accidentally Quadratic
Для более приземлённого удовольствия см. видеоподборку моих 19 разных способов добраться на работу в сентябре — я был слишком занят, чтобы продолжать эксперимент в этом месяце.
- 35208 reads
Who's online
There are currently 0 users and 7 guests online.
Copyright © Home Co. Ltd. LLC, 2008-2022 - Kurgan-Telecom.Ru - VDS/VPS Хостинг в Кургане - All Rights Reserved

