Вычисляем по IP: как бороться со спамом в социальной сети
Спам в социальных сетях и мессенджерах — это боль. Боль и для честных пользователей, и для разработчиков. Как с ней борются в Badoo, рассказал Михаил Овчинников на Highload++, далее текстовая версия этого доклада.
О спикере: Михаил Овчинников работает в Badoo и последние пять лет занимается антиспамом.
В Badoo зарегистрировано 390 миллионов пользователей (данные на октябрь 2017). Если сравнивать размер аудитории сервиса с населением России, то можно сказать, что в нашей стране по статистике каждых 100 млн человек охраняет 500 тысяч полицейских, а в Badoo каждые 100 млн пользователей защищает от спама всего один сотрудник Антиспама. Но даже такое небольшое количество программистов способно защитить пользователей от разных неприятностей в интернете.
У нас большая аудитория, и в ней могут быть разные пользователи:
С кем приходится сражаться
Спам бывает разный, часто его вообще не отличить от поведения обычного пользователя. Он может быть ручной или автоматический — к нам тоже хотят попасть боты, которые занимаются автоматической рассылкой.
Это, конечно, шутка. В статье не будет информации, которая упростит жизнь спамерам.

Итак, с кем нам приходится сражаться? Это спамеры и мошенники.
Спам появился очень давно, с самого начала развития интернета. В нашем сервисе спамеры, как правило, пытаются зарегистрировать аккаунт, загрузив туда фотографию привлекательной девушки. В простейшем варианте они начинают рассылать самые очевидные виды спама — ссылки.
Более сложный вариант — когда люди не шлют ничего откровенного, не посылают никаких ссылок, ничего не рекламируют, но выманивают пользователя в более удобное для них место, например в мессенджеры: Skype, Viber, WhatsApp. Там они смогут без нашего контроля что угодно продавать пользователю, продвигать и т.д.
Но спамеры — это не самая большая проблема. Они действуют очевидно, и с ними легко бороться. Гораздо более сложные и интересные персонажи — это мошенники-скамеры, которые выдают себя за другого человека и стараются обмануть пользователей всеми способами, которые есть в интернете.
Конечно, действия и спамеров, и скамеров не всегда сильно отличаются от поведения обычных пользователей, которые тоже иногда так делают. Есть много формальных признаков и у тех, и у других, которые не позволяют четко провести границу между ними. Это практически никогда невозможно сделать.
Как боролись со спамом в Мезозойскую эру

Сначала я покажу простейшие методы борьбы со спамом, которые каждый может у себя реализовать. Потом подробно расскажу про более сложные системы, которые мы разработали с применением машинного обучения и прочей тяжелой артиллерии.
Простейшие способы борьбы со спамом
Ручная модерация
В любой сервис можно нанять модераторов, которые будут вручную просматривать контент пользователя и его профиль, и решать, что с этим пользователем делать. Обычно такой процесс выглядит, как поиск иголки в стоге сена. У нас огромное количество пользователей, модераторов меньше.

Кроме того, что модераторов очевидно нужно много, нужна большая инфраструктура. Но, на самом деле, самое сложное другое — возникает проблема: как, наоборот, защитить пользователей от модераторов.
Нужно сделать так, чтобы модераторы не получали доступа к персональным данным. Это важно, потому что модераторы теоретически могут тоже попытаться навредить. То есть нужен антиспам для антиспама, чтобы модераторы были под жестким контролем.
Очевидно, что всех пользователей таким образом не проверишь. Тем не менее модерация в любом случае нужна, потому что любым системам в дальнейшем нужно обучение и человеческая рука, которая будет определять, что делать с пользователем.
Сбор статистики
Можно попробовать использовать статистику — по каждому пользователю собирать различные параметры.
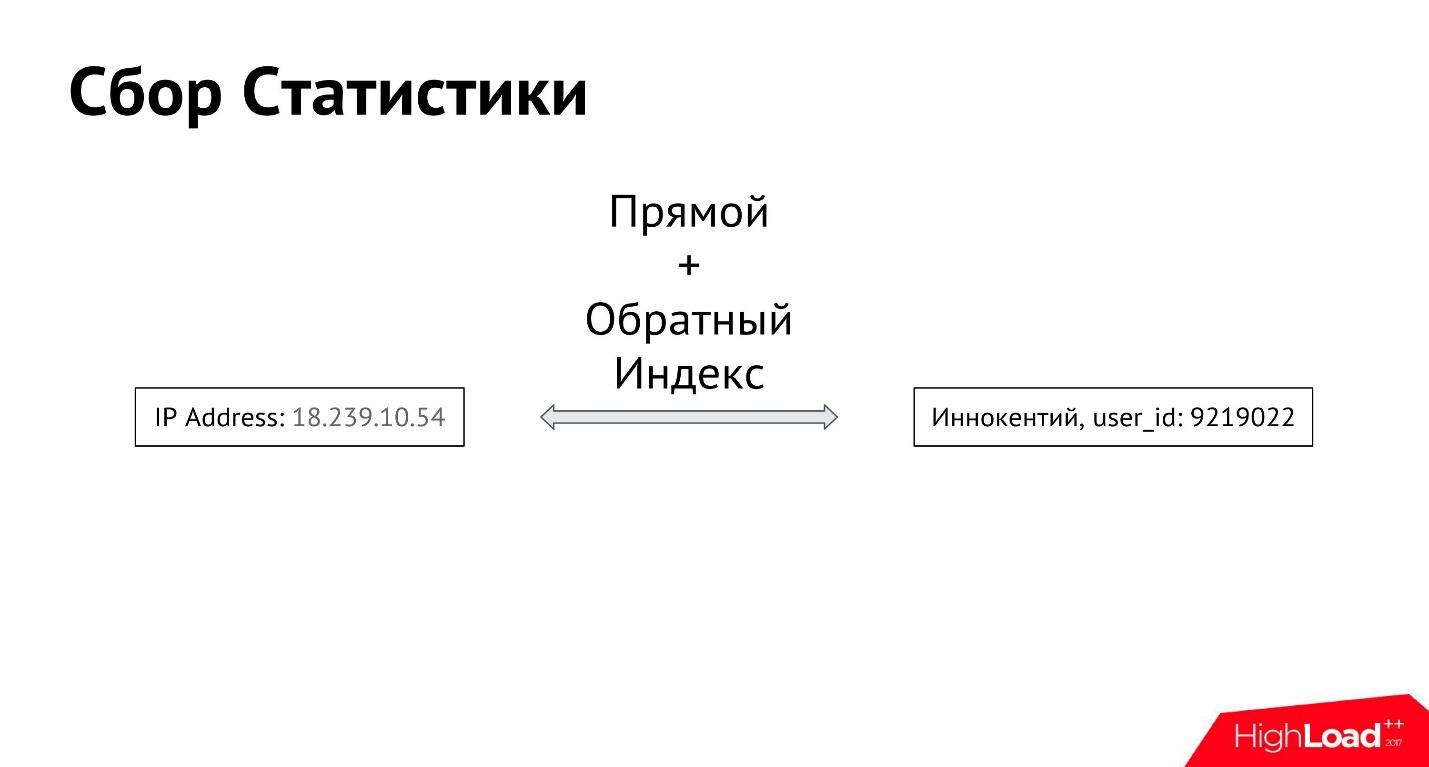
Пользователь Иннокентий заходит со своего IP-адреса. Первое, что мы делаем — логируем, с какого IP-адреса он зашел. Дальше строим между всеми IP-адресами и всеми пользователями прямой и обратный индекс, чтобы можно было получить все IP-адреса, с которых заходит определенный пользователь, а также всех пользователей, которые зашли с определенного IP-адреса.
Таким образом мы получаем связь между атрибутом и пользователем. Таких атрибутов может быть достаточно много. Мы можем начать собирать информацию не только об IP-адресах, но еще и фотографиях, устройствах с которых заходил пользователь — обо всем, что можем определить.
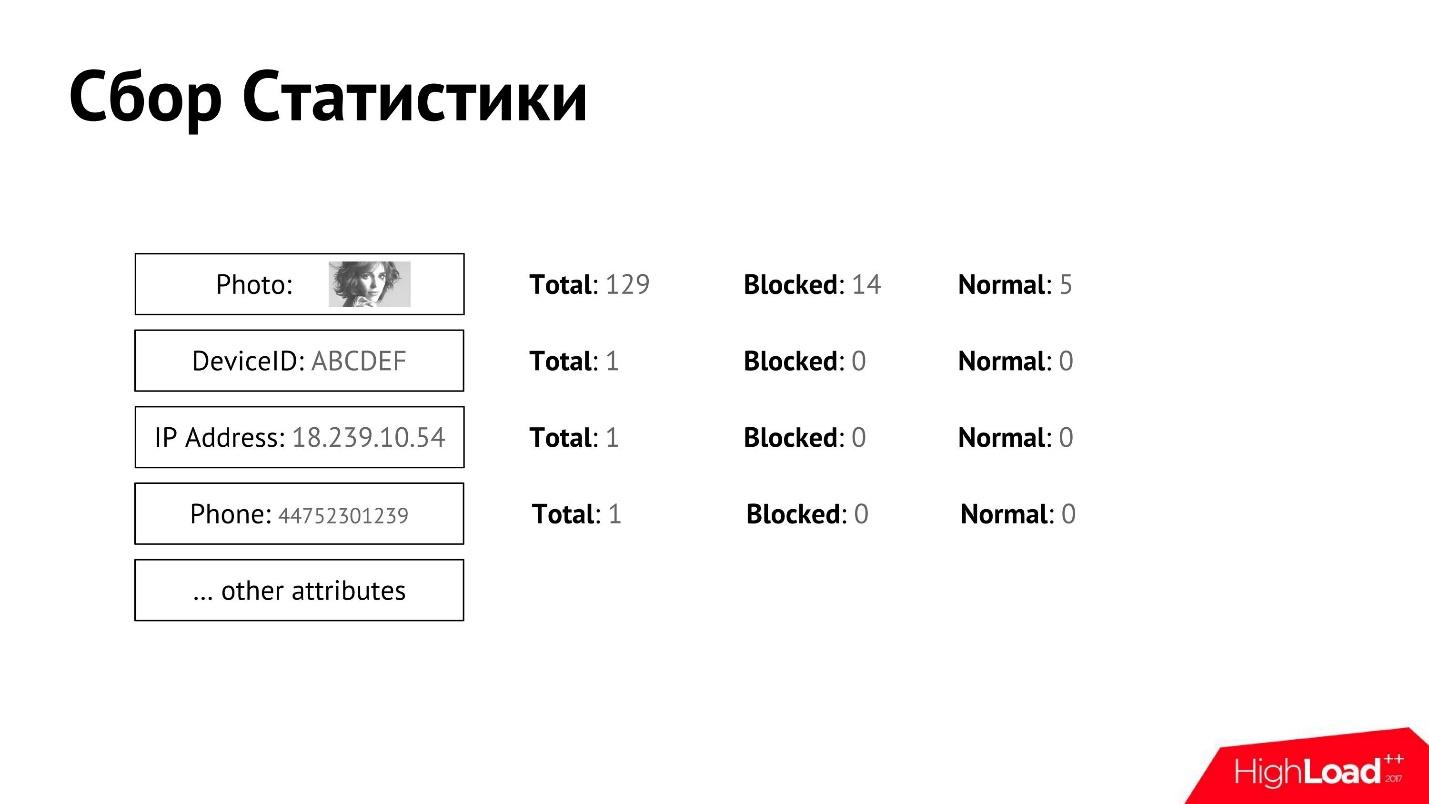
Мы собираем такую статистику и связываем ее с пользователем. Для каждого из атрибутов мы можем собирать подробные счетчики.
У нас есть ручная модерация, которая решает, какой пользователь хороший, какой плохой, и в какой-то момент пользователь блокируется или признается нормальным. Мы можем по каждому из атрибутов отдельно получить данные, сколько всего пользователей, сколько из них заблокировано, сколько признано нормальными.
Обладая такой статистикой по каждому из атрибутов, мы можем примерно определить, кто спамер, кто нет.

Допустим, у нас есть два IP-адреса — на одном 80% спамеров, на втором 1%. Очевидно, что первый гораздо более заспамленный, с ним надо что-то делать и применять какие-то санкции.
Самое простое — это написать эвристические правила. Например, если заблокированных пользователей больше 80%, а тех, кто признан нормальным — меньше 5%, то этот IP-адрес считается плохим. Дальше мы баним или что-то еще делаем со всеми пользователями с таким IP-адресом.
Сбор статистики из текстов
Помимо очевидных атрибутов, которые есть у пользователей, можно также заняться анализом текста. Можно автоматически разбирать пользовательские сообщения, вычленять из них все, что имеет отношение к спаму: упоминания мессенджеров, телефонов, email, ссылок, доменов и т.д., и по ним собирать точно такую же статистику.

Например, если какое-то доменное имя было отправлено в сообщениях 100 пользователями, из них 50 было заблокировано, значит, это доменное имя плохое. Его можно вносить в черные списки.
Мы получим большое количество дополнительной статистики по каждому из пользователей на основе текстов сообщений. Для этого никакого машинного обучения не нужно.
Стоп-слова
Помимо очевидных вещей — телефонов и ссылок — можно вычленять из текста фразы или слова, которые особенно характерны для спамеров. Можно вести такой список стоп-слов вручную.
Например, на аккаунтах спамеров и мошенников часто встречается фраза: «Здесь очень много фейков». Они пишут, что они вообще единственные здесь, кто настроен на что-то серьезное, все остальные фейки, которым ни в коем случае нельзя доверять.
На сайтах знакомств по статистике спамеры чаще, чем обычные люди, употребляют фразу: «Я ищу серьезные отношения». Вряд ли обычный человек так напишет на сайте знакомств — с вероятностью 70% это спамер, который пытается кого-то завлечь.
Поиск похожих аккаунтов
Обладая статистикой по атрибутам и по стоп-словам, найденным в текстах, можно построить систему для поиска похожих аккаунтов. Это нужно, чтобы находить и банить все аккаунты, созданные одним и тем же человеком. Спамер, который попал под блокировку может тут же зарегистрировать новый аккаунт.
Например, пользователь Гарольд заходит, регистрируется на сайте и предоставляет свои достаточно уникальные атрибуты: IP-адрес, фотографию, стоп-слово, которое он употребил. Может быть, он даже зарегистрировался с фейкового аккаунта Facebook.
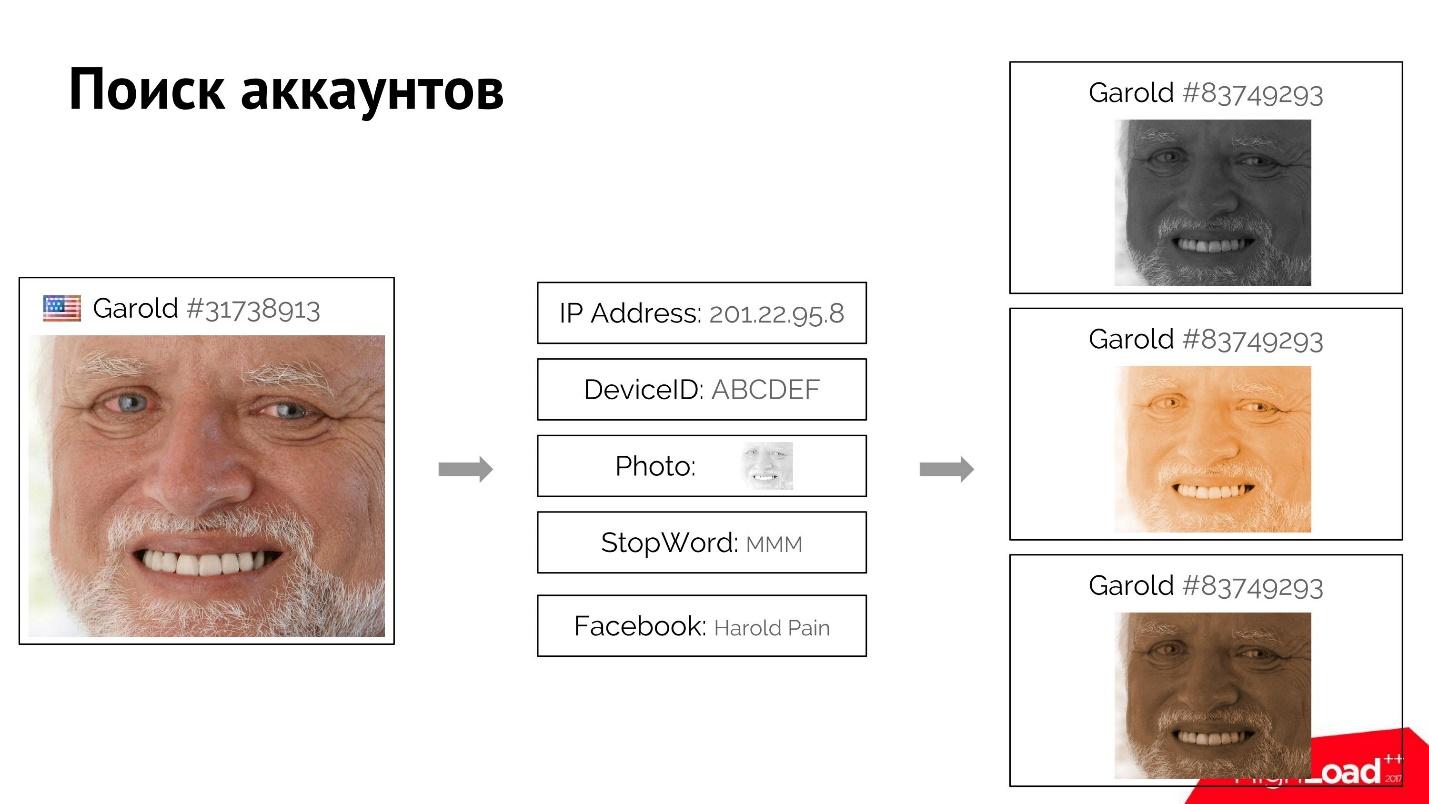
Мы можем найти всех пользователей, похожих на него, у которых совпадают один или несколько из этих атрибутов. Когда мы точно знаем, что эти пользователи связаны, с помощью того самого прямого и обратного индекса мы находим атрибуты, а по ним уже всех пользователей, и ранжируем их. Если, допустим первого Гарольда мы заблокируем, то остальных тоже легко «убить» с помощью этой системы.
Все способы, которые я сейчас описал, очень простые: легко собрать статистику, легко потом по этим атрибутам искать пользователей. Но, несмотря на лёгкость, с помощью таких простых штук — простой модерации, простой статистики, простых стоп-слов — удаётся победить 50% спама.
В нашей компании за первые полгода работы отдел Антиспама победил 50% спама. Остальные 50%, как известно, даются гораздо сложнее.
Как усложнить жизнь спамерам
Спамеры что-то выдумывают, пытаясь усложнить жизнь нам, а мы пытаемся бороться с ними. Это бесконечная война. Их гораздо больше, чем нас, и на каждый наш шаг они придумывают свою многоходовочку.
К сожалению, нас на такие конференции не приглашают.
Но мы можем усложнить спамерам жизнь. Например, вместо того чтобы напрямую показывать пользователю окошко «Вы заблокированы», можно применить так называемый Stealth banning — это когда мы пользователю не говорим о том, что он забанен. Он даже не должен об этом подозревать.

Пользователь попадает в песочницу (Silent Hill), где как будто все настоящее: можно отправлять сообщения, голосовать, но на самом деле это все уходит в пустоту, в туман. Никто это никогда не увидит и не услышит, никто не получит его сообщений и голосов.
У нас был случай, когда один спамер долго спамил, продвигал свои нехорошие товары и услуги, а через полгода решил воспользоваться сервисом по назначению. Он зарегистрировал свой настоящий аккаунт: реальные фотографии, имя и т.д. Естественно, наша система поиска похожих аккаунтов быстро его вычислила и поместила в Stealth ban. После этого он еще в течение полугода писал в пустоту о том, что ему очень одиноко, никто не отвечает. В общем, изливал всю свою душу туману Silent Hill, но не получал никакого ответа.
Спамеры, конечно, не дураки. Они пытаются каким-то образом определить, что они попали в песочницу и что их заблокировали, бросить старый аккаунт и найти новый. У нас даже появляется иногда мысль о том, что хорошо бы несколько таких спамеров отправить в песочницу вместе, чтобы они там друг другу уже продавали все, что хотят, и развлекались, как угодно. Но пока мы до этого не дошли, а придумываем другие способы, например, фото- и телефонная верификация.

Как известно, спамеру, который является ботом, а не человеком сложно пройти верификацию по телефону или по фотографии.
В нашем случае верификация по фотографии выглядит так: пользователя просят сфотографироваться с определенным жестом, полученная фотография сравнивается с фотографиями, которые уже загружены в профиль. Если лица одинаковые, то, скорее всего, человек настоящий, загрузил свои реальные фотографии и можно от него на какое-то время отстать.
Спамерам пройти эту проверку нелегко. У нас даже внутри компании появилась небольшая игра, которая называется «Угадай, кто спамер». Дается четыре фото, нужно понять, кто из них является спамером.
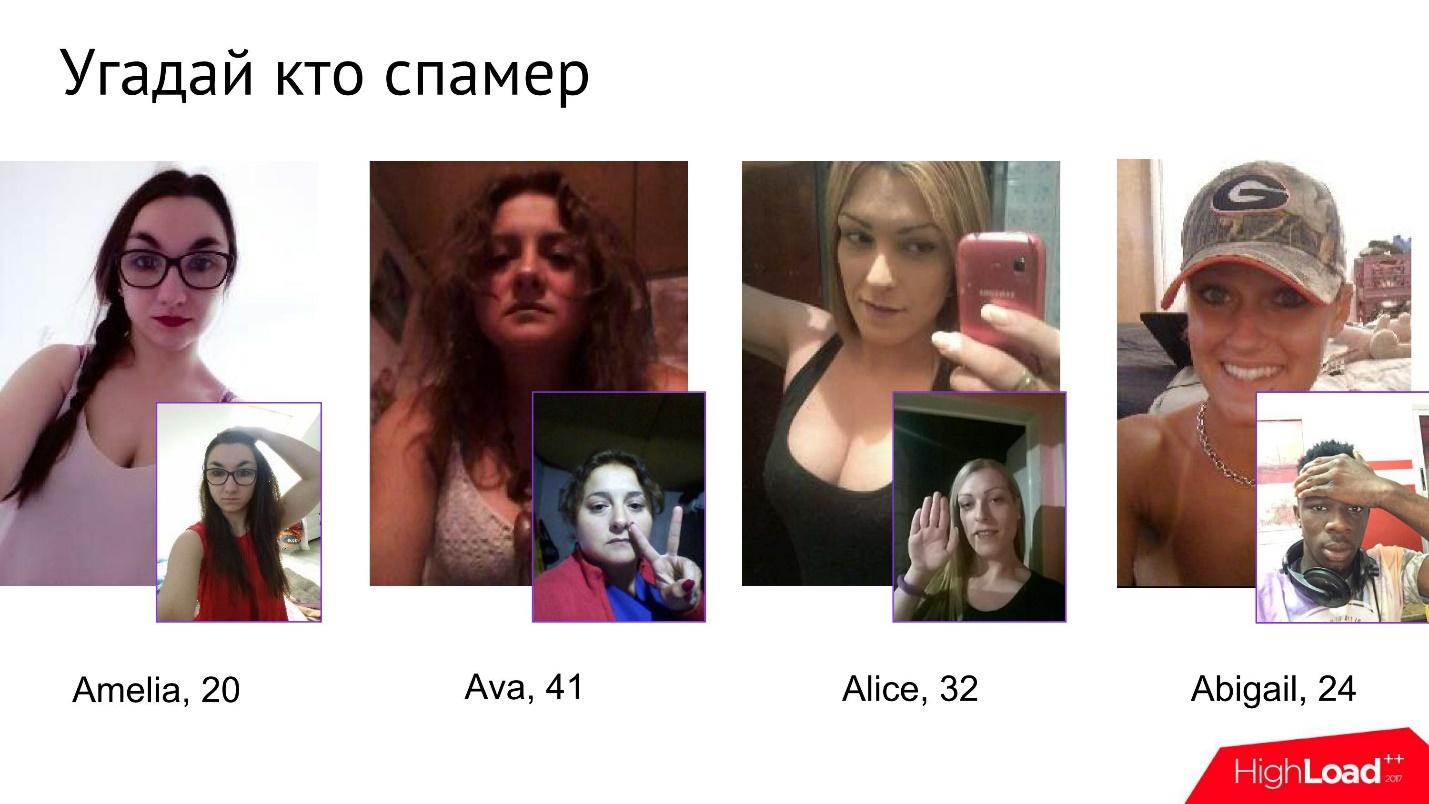
На первый взгляд, эти девушки выглядят совершенно безобидно, но как только начинают проходить фотоверификацию, то с какого-то момента становится понятно, что одна из них совершенно не та, за кого себя выдает.
В любом случае спамерам тяжело с фотоверификацией бороться. Они действительно страдают, пытаются как-то ее обойти, обмануть, и демонстрируют все свои навыки фотошопа.

Спамеры делают все, что могут, и иногда думают, наверное, что это все полностью обрабатывается какими-то невероятными современными технологиями, которые настолько плохо построены, что их так легко обмануть.
Они не знают, что каждую фотографию потом еще перепроверяют вручную модераторы.
Нет времени!
На самом деле, несмотря на то что мы придумываем различные способы, как усложнить спамерам жизнь, обычно не хватает времени, потому что антиспам должен работать мгновенно. Он должен найти и обезвредить пользователя еще до того, как он начал свою негативную активность.
Самое лучшее, что можно сделать — это еще на этапе регистрации определить, что пользователь является не очень хорошим. Это можно сделать, например, с помощью кластеризации.
Кластеризация пользователей
Мы можем прямо после регистрации собрать всю возможную информацию. У нас еще нет ни девайсов, с которых пользователь заходит, ни фотографий, нет никакой статистики. Нам не за что его отправлять на верификацию, он еще не сделал ничего подозрительного. Но мы уже обладаем первичной информацией:
Всю эту информацию можно использовать для того, чтобы находить кластеры пользователей. Мы используем простой и популярный алгоритм кластеризации K-means. Он везде прекрасно имплементирован, поддерживается в любых библиотеках MachineLearning, прекрасно параллелится, быстро работает. Есть стриминговые варианты этого алгоритма, которые позволяют на лету распределять пользователей на кластеры. Даже в наших объемах все это работает достаточно быстро.
Получив такие группы пользователей (кластеры), мы можем делать любые действия. Если пользователи очень похожи (кластер сильно связанный), то, скорее всего, это массовая регистрация, ее нужно сразу же пресекать. Пользователь еще не успел ничего сделать, только нажал кнопку «Зарегистрироваться» — а все, он уже попал в песочницу.
По кластерам можно собирать статистику — если 50% кластера заблокировано, то остальные 50% можно отправить на верификацию, или отдельно все кластеры модерировать вручную, просматривать те атрибуты, по которым они совпадают, и принимать решение. На основе таких данных, аналитики могут выделять паттерны.
Паттерны
Паттерны — это наборы простейших атрибутов пользователей, которые нам сразу известны. Некоторые из паттернов на самом деле очень эффективно работают против определенных типов спамеров.
Например, рассмотрим сочетание трех абсолютно независимых, достаточно общих атрибутов:
Эти три атрибута, казалось бы, в отдельности ничего из себя не представляющие, вместе дают вероятность того, что это спамер, практически 90%.
Таких паттернов можно извлечь сколько угодно на каждый тип спамера. Это гораздо эффективнее и проще, чем просматривать вручную все аккаунты или даже кластеры.
Кластеризация текстов
Помимо кластеризации пользователей по атрибутам, можно находить пользователей, которые пишут одинаковые тексты. Конечно, это уже не так просто. Дело в том, что наш сервис работает на очень многих языках. Более того, пользователи часто пишут с сокращениями, на сленге, иногда с ошибками. Ну а сами сообщения обычно очень короткие, буквально 3–4 слова (примерно 25 символов).
Соответственно, если мы хотим находить похожие тексты среди миллиардов сообщений, которые пишут пользователи, нам нужно придумать что-то необычное. Если пытаться использовать классические методы на основе анализа морфологии и настоящего честного процессинга языка, то со всеми этими ограничениями, сленгами, сокращениями и кучей языков, это сделать очень сложно.
Можно поступить чуть более просто — применить алгоритм n-gram. Каждое сообщение, которое появляется, разбивается на n-граммы. Если n=2, то это биграммы (пары букв). Постепенно все сообщение разделяется на пары букв и собирается статистика, сколько раз каждая биграмма встречается в тексте.

На биграммах можно не останавливаться, а добавить триграммы, скипграммы (статистика по буквам через 1, 2 и т.д. букв). Чем больше мы получим информации, тем лучше. Но даже биграммы уже достаточно хорошо работают.
Дальше мы из биграмм каждого сообщения получаем вектор, длина которого равна квадрату длины алфавита.
С этим вектором очень удобно работать и его кластеризовать, потому что:
Но это еще не все. К сожалению, если мы просто соберем все сообщения, которые похожи по частотности биграмм, то получим сообщения, которые похожи по частотности биграмм. При этом они не обязаны быть на самом деле хоть как-то похожи по смыслу. Часто встречаются длинные тексты, у которых векторы очень близки, практически совпадают, но сами тексты совершенно разные. Более того начиная с определенной длины текста этот метод кластеризации вообще перестанет работать, т.к. частоты биграмм сравняются.

Поэтому нужно добавить фильтрацию. Так как кластеры уже есть, они достаточно маленькие, мы легко можем внутри кластера сделать фильтрацию применив Stemming или Bag of Words. Внутри маленького кластера можно буквально все сообщения со всеми сравнить, и получить тот кластер, в котором гарантированно находятся одинаковые сообщения, которые совпадают не только по статистике, но и на самом деле.
Итак, мы сделали кластеризацию — и, тем не менее, для нас (и для кластеризации) очень важно знать правду о пользователе. Если он пытается от нас скрыть правду, то нам нужно предпринять какие-то действия.
Сокрытие информации
Типичный вид сокрытия информации — это VPN, TOR, Proxy, Анонимайзеры. Пользователь использует их, пытаясь сделать вид, что он из Америки, хотя на самом деле он из Нигерии.
Для того, чтобы победить эту проблему, мы взяли самый известный учебник «Как вычислить по IP».

С помощью этого учебника мы написали классификатор VPN — то есть такой классификатор, который получает на вход IP-адрес и на выходе говорит, является ли этот IP-адрес VPN, Proxy или нет.
Для реализации классификатора нам понадобится несколько ингредиентов:
Взяв всю эту информацию, можно построить классификатор, который в итоге будет говорить, является ли IP-адрес VPN или нет.
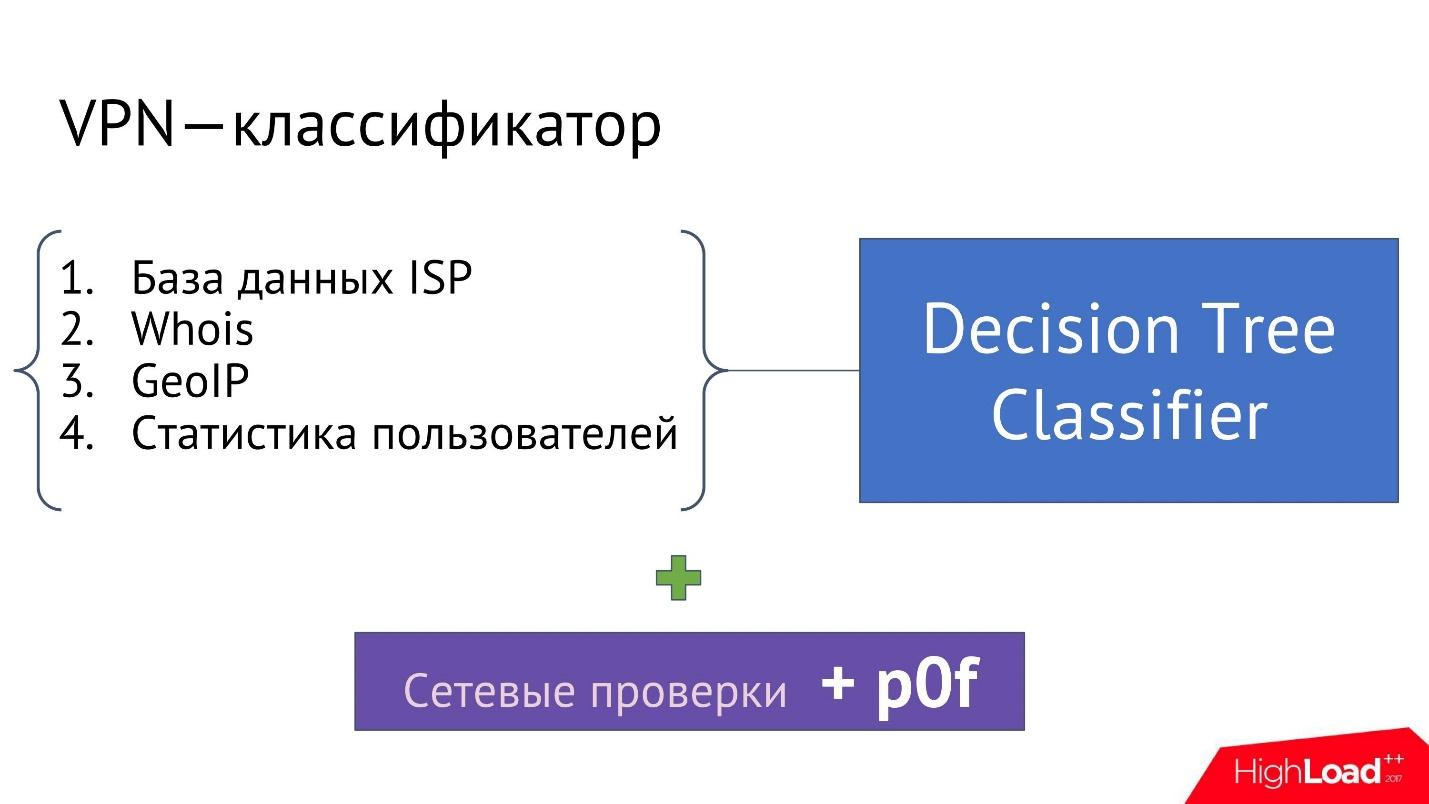
Мы выбрали деревья решений, потому что они очень хорошо умеют находить те самые паттерны — конкретные сочетания провайдеров, стран, статистики и т.д., которые в итоге позволяют определить, что IP-адрес является VPN.
Конечно, эти данные очень общие. Как бы мы хорошо не обучали классификатор, как бы мы не старались применять advanced-техники, он все равно не будет работать со 100% точностью. Поэтому здесь ключевым фактором являются дополнительные сетевые проверки.
Как только мы получили информацию о том, что IP-адрес якобы принадлежит VPN, мы можем на самом деле проверить, что же этот IP-адрес из себя представляет. Можно попытаться к нему подключиться, посмотреть, какие на нем открыты порты. Если там SOCKS-proxy, можно попробовать открыть соединение и точно определить является данный IP-адрес анонимайзером или нет.
Кроме того, есть еще замечательная технология, внедрение которой у нас пока в планах, которая называется p0f. Это утилита, которая на сетевом уровне делает fingerprinting трафика и позволяет сразу определить, что находится на той стороне соединения: обычный пользовательский клиент, VPN-клиент, Proxy и т.д. Утилита содержит большой набор паттернов, которые все это определяют.
Наиболее подозрительное действие
После того, как мы написали различные системы, кластеризаторы, классификаторы, собрали статистику, мы задумались: что самого подозрительного пользователь может совершить на нашем сервисе? Зарегистрироваться — это уже подозрительно! Если пользователь зарегистрировался, то мы сразу начинаем на него смотреть с очень хитрым прищуром и всячески его анализировать, пытаясь понять, что же он имел ввиду.
У нас часто возникает внутреннее желание — а не забанить ли нам сразу всех после регистрации? Это бы значительно облегчило работу отдела Антиспама. Мы сразу сможем пить чай в 2 раза дольше, и никаких проблем у нас не будет.
Чтобы такие мысли пресекать не только у себя, но и у систем, которые мы пишем, и не банить всех хороших пользователей, особенно сразу после регистрации, мы вынуждены создавать системы, которые борются с другими нашими системами, то есть организуют сами себе ограничения.

Как можно себя ограничить, чтобы не банить хороших пользователей, не ошибиться и не запутаться?
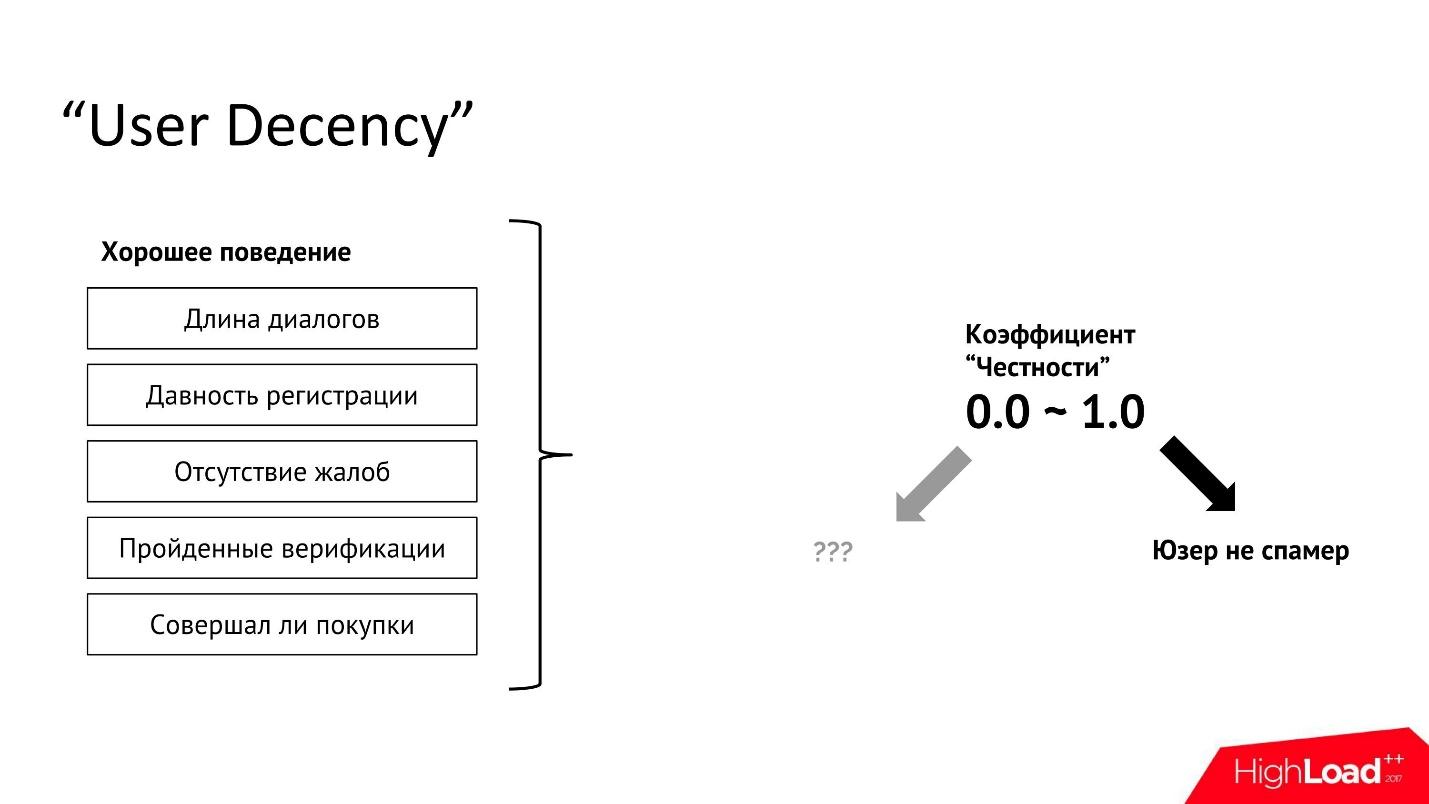
«User Decency»
Классифицируем пользователей по честности — сделаем изолированную модель, которая будет брать все положительные характеристики пользователя и делать по ним анализ.
Пример характеристик «хорошего» поведения:
На наборе данных всех отдельных исключительно хороших характеристик пользователя можно обучить классификатор или регрессию. У нас работает простая логистическая регрессия. Эта модель легко портируется, поскольку представляет из себя просто набор коэффициентов, и ее легко реализовать в любой системе и на любом языке, она очень хорошо переносится между платформами и инфраструктурами.
Взяв пользователя и прогнав его через эту модель, мы получим коэффициент, который мы называем «коэффициентом честности». Если он равен нулю, то, как правило, это значит, что у нас почти нет информации об этом пользователе. Тогда никакой дополнительной информации мы из классификации не получаем.
Если коэффициент честности пользователя равен 1, то, скорее всего, пользователь представляет из себя хорошего парня, мы его трогать не будем — никаких верификаций и бана к нему не придет.
Такая изолированная штука позволяет нам предотвратить многие типичные ошибки.
False positive
Второе, что можно сделать — искать различные ложноположительные срабатывания. Бывает, что пользователи случайно заходят с одного IP-адреса. Например, двое сидят в интернет-кафе, даже компьютер может быть у них один и тот же. Браузер, fingerprint, который мы считаем по компьютеру, по браузеру, по устройству — все будет абсолютно совпадать, и мы можем посчитать, что оба пользователя являются спамерами, хотя не факт, что они как-то связаны.
Другой пример: хороший пользователь в диалоге со спамером может переспросить в ответ на рекламу: «Эй, я не понял — что такое Pornhub — зачем ты мне его рекламируешь?» В такой момент система видит, что пользователь написал стоп-слово и может посчитать, что этот пользователь является спамером и его нужно как можно скорее забанить.
Поэтому нам приходится заниматься поиском аномалий. Мы берем пользователей, их атрибуты, и ищем среди них тех пользователей, которые попали в плохую компанию совершенно случайно.
Для примера возьмем стоп-слово «Pornhub». По каждому стоп-слову у нас есть статистика всех пользователей, которые когда-либо его употребляли.
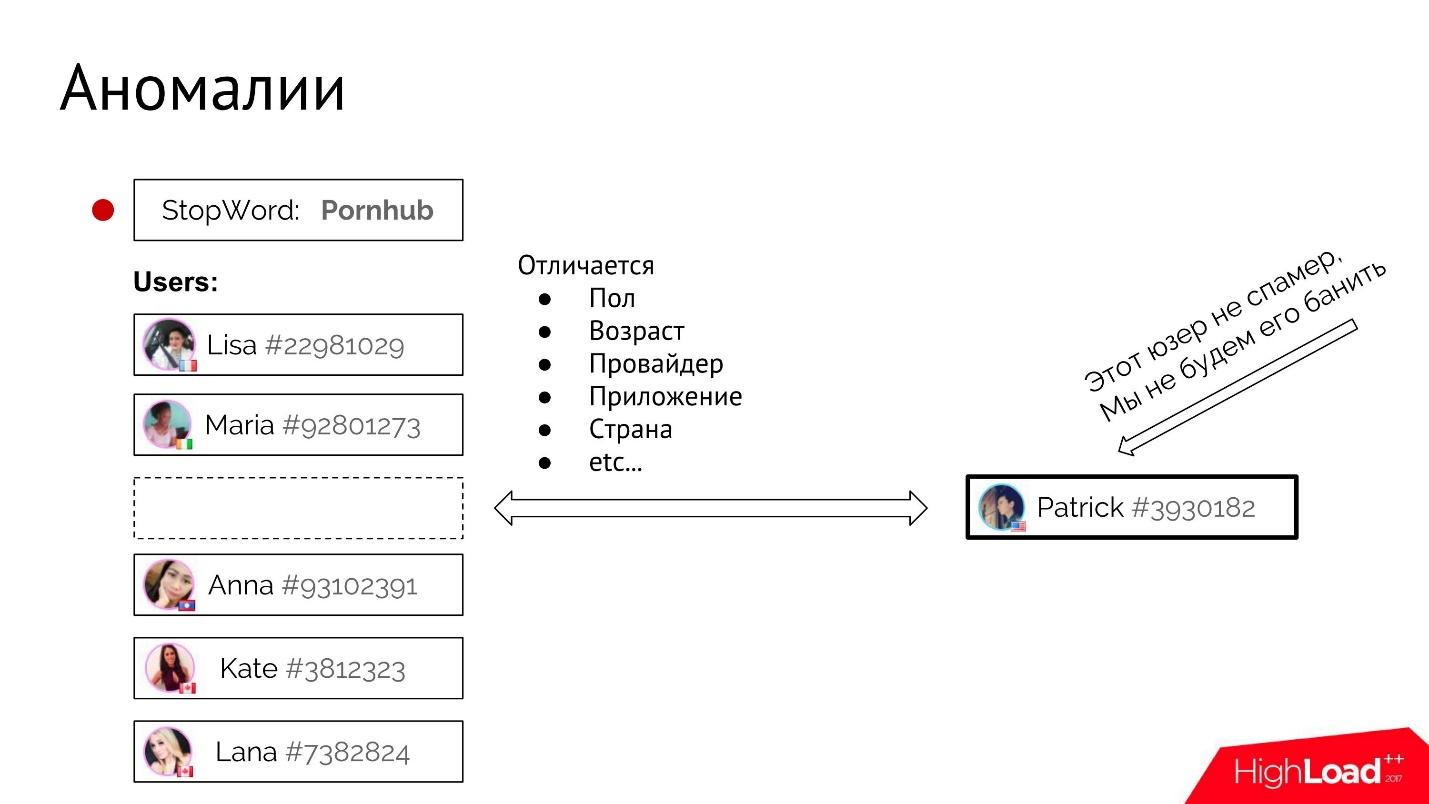
В какой-то момент новый пользователь Патрик употребляет то же самое стоп-слово, и мы должны добавить его в эту плохую компанию и забанить.
Здесь нужно проверить, отличается ли новый пользователь Патрик от всех старых, уже известных спамеров. Можно сравнить его типовые атрибуты: пол, возраст, провайдер, приложение, страна и т.д. Здесь нам важно понять, насколько велико «расстояние» в этом пространстве атрибутов между пользователем и основной группой. Если оно очень большое, то Патрик, скорее всего, попал туда случайно. Он ничего плохого не имел в виду, его не стоит сразу банить, а лучше отправить на ручную проверку.
Когда мы построили такую систему, у нас стало гораздо меньше случаться типовых ложноположительных срабатываний.
Универсальный мега-классификатор
Вы можете спросить — а почему бы не сделать сразу большую классную систему с MachineLearning, нейросетями и деревьями решений, которая будет получать на вход всю информацию о пользователях и выдавать просто 0 или 1 — человек спамер или нет.
Пытаясь создать одну универсальную модель, очень легко прийти к ситуации, когда перед нами окажется черный ящик, который сложно контролировать. В нем хорошее от плохого не отделено, система сама от себя никак не изолирована, и от ошибок защищена только ручной проверкой и косвенными метрикам. К тому же на большом объёме данных собрать всю информацию и статистику, чтобы подать мега-системе на вход, достаточно сложно.
Более того, все известные системы машинного обучения представляют собой не одну модель — это десяток моделей. Любой голосовой помощник или система распознавания лиц — это несколько моделей, соединенных в одну очень сложную систему.
В итоге нам стало понятно, что гораздо более правильным (с нашей точки зрения) является путь, когда создаются отдельные классификаторы и системы кластеризации, которые решают свою отдельную задачу. Идеально, чтобы, как в нашем случае, на каждый отдельный тип спама создавалась отдельная модель и отдельно же контролировалась различными способами: другими моделям, косвенными метриками, а также вручную. Только так можно будет надеяться избежать большинства ложных срабатываний.
О спикере: Михаил Овчинников работает в Badoo и последние пять лет занимается антиспамом.
В Badoo зарегистрировано 390 миллионов пользователей (данные на октябрь 2017). Если сравнивать размер аудитории сервиса с населением России, то можно сказать, что в нашей стране по статистике каждых 100 млн человек охраняет 500 тысяч полицейских, а в Badoo каждые 100 млн пользователей защищает от спама всего один сотрудник Антиспама. Но даже такое небольшое количество программистов способно защитить пользователей от разных неприятностей в интернете.
У нас большая аудитория, и в ней могут быть разные пользователи:
- Хорошие и очень хорошие, наши любимые платящие клиенты;
- Плохие — те, кто, наоборот, пытаются на нас заработать: рассылают спам, выманивают деньги, занимаются мошенничеством.
С кем приходится сражаться
Спам бывает разный, часто его вообще не отличить от поведения обычного пользователя. Он может быть ручной или автоматический — к нам тоже хотят попасть боты, которые занимаются автоматической рассылкой.
Возможно, вы тоже когда-то писали ботов — занимались созданием скриптов для автоматического постинга. Если вы этим занимаетесь и сейчас, то лучше дальше не читайте — вам нельзя ни в коем случае узнать то, что я сейчас расскажу.
Это, конечно, шутка. В статье не будет информации, которая упростит жизнь спамерам.
Итак, с кем нам приходится сражаться? Это спамеры и мошенники.
Спам появился очень давно, с самого начала развития интернета. В нашем сервисе спамеры, как правило, пытаются зарегистрировать аккаунт, загрузив туда фотографию привлекательной девушки. В простейшем варианте они начинают рассылать самые очевидные виды спама — ссылки.
Более сложный вариант — когда люди не шлют ничего откровенного, не посылают никаких ссылок, ничего не рекламируют, но выманивают пользователя в более удобное для них место, например в мессенджеры: Skype, Viber, WhatsApp. Там они смогут без нашего контроля что угодно продавать пользователю, продвигать и т.д.
Но спамеры — это не самая большая проблема. Они действуют очевидно, и с ними легко бороться. Гораздо более сложные и интересные персонажи — это мошенники-скамеры, которые выдают себя за другого человека и стараются обмануть пользователей всеми способами, которые есть в интернете.
Конечно, действия и спамеров, и скамеров не всегда сильно отличаются от поведения обычных пользователей, которые тоже иногда так делают. Есть много формальных признаков и у тех, и у других, которые не позволяют четко провести границу между ними. Это практически никогда невозможно сделать.
Как боролись со спамом в Мезозойскую эру
- Самое простое, что можно было делать — это писать на каждый вид спама отдельные регулярные выражения и заносить каждое нехорошее слово и каждый отдельный домен в эту регулярку. Все это делалось вручную, и, конечно, было максимально неудобно и неэффективно.
- Можно вручную находить сомнительные IP-адреса и заносить их в config сервера, чтобы подозрительные пользователи больше никогда не заходили на ваш ресурс. Это неэффективно, потому что IP-адреса постоянно переназначаются, перераспределяются.
- Писать одноразовые скрипты на каждый вид спамера или бота, грепать их логи, вручную находить закономерности. Если чуть-чуть что-то меняется в поведении спамера, все перестает работать — тоже совершенно неэффективно.
Сначала я покажу простейшие методы борьбы со спамом, которые каждый может у себя реализовать. Потом подробно расскажу про более сложные системы, которые мы разработали с применением машинного обучения и прочей тяжелой артиллерии.
Простейшие способы борьбы со спамом
Ручная модерация
В любой сервис можно нанять модераторов, которые будут вручную просматривать контент пользователя и его профиль, и решать, что с этим пользователем делать. Обычно такой процесс выглядит, как поиск иголки в стоге сена. У нас огромное количество пользователей, модераторов меньше.
Кроме того, что модераторов очевидно нужно много, нужна большая инфраструктура. Но, на самом деле, самое сложное другое — возникает проблема: как, наоборот, защитить пользователей от модераторов.
Нужно сделать так, чтобы модераторы не получали доступа к персональным данным. Это важно, потому что модераторы теоретически могут тоже попытаться навредить. То есть нужен антиспам для антиспама, чтобы модераторы были под жестким контролем.
Очевидно, что всех пользователей таким образом не проверишь. Тем не менее модерация в любом случае нужна, потому что любым системам в дальнейшем нужно обучение и человеческая рука, которая будет определять, что делать с пользователем.
Сбор статистики
Можно попробовать использовать статистику — по каждому пользователю собирать различные параметры.
Пользователь Иннокентий заходит со своего IP-адреса. Первое, что мы делаем — логируем, с какого IP-адреса он зашел. Дальше строим между всеми IP-адресами и всеми пользователями прямой и обратный индекс, чтобы можно было получить все IP-адреса, с которых заходит определенный пользователь, а также всех пользователей, которые зашли с определенного IP-адреса.
Таким образом мы получаем связь между атрибутом и пользователем. Таких атрибутов может быть достаточно много. Мы можем начать собирать информацию не только об IP-адресах, но еще и фотографиях, устройствах с которых заходил пользователь — обо всем, что можем определить.
Мы собираем такую статистику и связываем ее с пользователем. Для каждого из атрибутов мы можем собирать подробные счетчики.
У нас есть ручная модерация, которая решает, какой пользователь хороший, какой плохой, и в какой-то момент пользователь блокируется или признается нормальным. Мы можем по каждому из атрибутов отдельно получить данные, сколько всего пользователей, сколько из них заблокировано, сколько признано нормальными.
Обладая такой статистикой по каждому из атрибутов, мы можем примерно определить, кто спамер, кто нет.
Допустим, у нас есть два IP-адреса — на одном 80% спамеров, на втором 1%. Очевидно, что первый гораздо более заспамленный, с ним надо что-то делать и применять какие-то санкции.
Самое простое — это написать эвристические правила. Например, если заблокированных пользователей больше 80%, а тех, кто признан нормальным — меньше 5%, то этот IP-адрес считается плохим. Дальше мы баним или что-то еще делаем со всеми пользователями с таким IP-адресом.
Сбор статистики из текстов
Помимо очевидных атрибутов, которые есть у пользователей, можно также заняться анализом текста. Можно автоматически разбирать пользовательские сообщения, вычленять из них все, что имеет отношение к спаму: упоминания мессенджеров, телефонов, email, ссылок, доменов и т.д., и по ним собирать точно такую же статистику.
Например, если какое-то доменное имя было отправлено в сообщениях 100 пользователями, из них 50 было заблокировано, значит, это доменное имя плохое. Его можно вносить в черные списки.
Мы получим большое количество дополнительной статистики по каждому из пользователей на основе текстов сообщений. Для этого никакого машинного обучения не нужно.
Стоп-слова
Помимо очевидных вещей — телефонов и ссылок — можно вычленять из текста фразы или слова, которые особенно характерны для спамеров. Можно вести такой список стоп-слов вручную.
Например, на аккаунтах спамеров и мошенников часто встречается фраза: «Здесь очень много фейков». Они пишут, что они вообще единственные здесь, кто настроен на что-то серьезное, все остальные фейки, которым ни в коем случае нельзя доверять.
На сайтах знакомств по статистике спамеры чаще, чем обычные люди, употребляют фразу: «Я ищу серьезные отношения». Вряд ли обычный человек так напишет на сайте знакомств — с вероятностью 70% это спамер, который пытается кого-то завлечь.
Поиск похожих аккаунтов
Обладая статистикой по атрибутам и по стоп-словам, найденным в текстах, можно построить систему для поиска похожих аккаунтов. Это нужно, чтобы находить и банить все аккаунты, созданные одним и тем же человеком. Спамер, который попал под блокировку может тут же зарегистрировать новый аккаунт.
Например, пользователь Гарольд заходит, регистрируется на сайте и предоставляет свои достаточно уникальные атрибуты: IP-адрес, фотографию, стоп-слово, которое он употребил. Может быть, он даже зарегистрировался с фейкового аккаунта Facebook.
Мы можем найти всех пользователей, похожих на него, у которых совпадают один или несколько из этих атрибутов. Когда мы точно знаем, что эти пользователи связаны, с помощью того самого прямого и обратного индекса мы находим атрибуты, а по ним уже всех пользователей, и ранжируем их. Если, допустим первого Гарольда мы заблокируем, то остальных тоже легко «убить» с помощью этой системы.
Все способы, которые я сейчас описал, очень простые: легко собрать статистику, легко потом по этим атрибутам искать пользователей. Но, несмотря на лёгкость, с помощью таких простых штук — простой модерации, простой статистики, простых стоп-слов — удаётся победить 50% спама.
В нашей компании за первые полгода работы отдел Антиспама победил 50% спама. Остальные 50%, как известно, даются гораздо сложнее.
Как усложнить жизнь спамерам
Спамеры что-то выдумывают, пытаясь усложнить жизнь нам, а мы пытаемся бороться с ними. Это бесконечная война. Их гораздо больше, чем нас, и на каждый наш шаг они придумывают свою многоходовочку.
Уверен, где-то проходят конференции спамеров, на которых докладчики рассказывают, как они победили Антиспам Badoo, про свои KPI, или про то, как построить масштабируемый отказоустойчивый спам с применением моднейших технологий.
К сожалению, нас на такие конференции не приглашают.
Но мы можем усложнить спамерам жизнь. Например, вместо того чтобы напрямую показывать пользователю окошко «Вы заблокированы», можно применить так называемый Stealth banning — это когда мы пользователю не говорим о том, что он забанен. Он даже не должен об этом подозревать.
Пользователь попадает в песочницу (Silent Hill), где как будто все настоящее: можно отправлять сообщения, голосовать, но на самом деле это все уходит в пустоту, в туман. Никто это никогда не увидит и не услышит, никто не получит его сообщений и голосов.
У нас был случай, когда один спамер долго спамил, продвигал свои нехорошие товары и услуги, а через полгода решил воспользоваться сервисом по назначению. Он зарегистрировал свой настоящий аккаунт: реальные фотографии, имя и т.д. Естественно, наша система поиска похожих аккаунтов быстро его вычислила и поместила в Stealth ban. После этого он еще в течение полугода писал в пустоту о том, что ему очень одиноко, никто не отвечает. В общем, изливал всю свою душу туману Silent Hill, но не получал никакого ответа.
Спамеры, конечно, не дураки. Они пытаются каким-то образом определить, что они попали в песочницу и что их заблокировали, бросить старый аккаунт и найти новый. У нас даже появляется иногда мысль о том, что хорошо бы несколько таких спамеров отправить в песочницу вместе, чтобы они там друг другу уже продавали все, что хотят, и развлекались, как угодно. Но пока мы до этого не дошли, а придумываем другие способы, например, фото- и телефонная верификация.
Как известно, спамеру, который является ботом, а не человеком сложно пройти верификацию по телефону или по фотографии.
В нашем случае верификация по фотографии выглядит так: пользователя просят сфотографироваться с определенным жестом, полученная фотография сравнивается с фотографиями, которые уже загружены в профиль. Если лица одинаковые, то, скорее всего, человек настоящий, загрузил свои реальные фотографии и можно от него на какое-то время отстать.
Спамерам пройти эту проверку нелегко. У нас даже внутри компании появилась небольшая игра, которая называется «Угадай, кто спамер». Дается четыре фото, нужно понять, кто из них является спамером.
На первый взгляд, эти девушки выглядят совершенно безобидно, но как только начинают проходить фотоверификацию, то с какого-то момента становится понятно, что одна из них совершенно не та, за кого себя выдает.
В любом случае спамерам тяжело с фотоверификацией бороться. Они действительно страдают, пытаются как-то ее обойти, обмануть, и демонстрируют все свои навыки фотошопа.
Спамеры делают все, что могут, и иногда думают, наверное, что это все полностью обрабатывается какими-то невероятными современными технологиями, которые настолько плохо построены, что их так легко обмануть.
Они не знают, что каждую фотографию потом еще перепроверяют вручную модераторы.
Нет времени!
На самом деле, несмотря на то что мы придумываем различные способы, как усложнить спамерам жизнь, обычно не хватает времени, потому что антиспам должен работать мгновенно. Он должен найти и обезвредить пользователя еще до того, как он начал свою негативную активность.
Самое лучшее, что можно сделать — это еще на этапе регистрации определить, что пользователь является не очень хорошим. Это можно сделать, например, с помощью кластеризации.
Кластеризация пользователей
Мы можем прямо после регистрации собрать всю возможную информацию. У нас еще нет ни девайсов, с которых пользователь заходит, ни фотографий, нет никакой статистики. Нам не за что его отправлять на верификацию, он еще не сделал ничего подозрительного. Но мы уже обладаем первичной информацией:
- пол;
- возраст;
- страна регистрации;
- страна и провайдер IP;
- email-домен;
- оператор телефона (если есть);
- данные из fb (если есть) — сколько у него друзей, сколько залил фотографий, как давно он там зарегистрировался и т.д.
Всю эту информацию можно использовать для того, чтобы находить кластеры пользователей. Мы используем простой и популярный алгоритм кластеризации K-means. Он везде прекрасно имплементирован, поддерживается в любых библиотеках MachineLearning, прекрасно параллелится, быстро работает. Есть стриминговые варианты этого алгоритма, которые позволяют на лету распределять пользователей на кластеры. Даже в наших объемах все это работает достаточно быстро.
Получив такие группы пользователей (кластеры), мы можем делать любые действия. Если пользователи очень похожи (кластер сильно связанный), то, скорее всего, это массовая регистрация, ее нужно сразу же пресекать. Пользователь еще не успел ничего сделать, только нажал кнопку «Зарегистрироваться» — а все, он уже попал в песочницу.
По кластерам можно собирать статистику — если 50% кластера заблокировано, то остальные 50% можно отправить на верификацию, или отдельно все кластеры модерировать вручную, просматривать те атрибуты, по которым они совпадают, и принимать решение. На основе таких данных, аналитики могут выделять паттерны.
Паттерны
Паттерны — это наборы простейших атрибутов пользователей, которые нам сразу известны. Некоторые из паттернов на самом деле очень эффективно работают против определенных типов спамеров.
Например, рассмотрим сочетание трех абсолютно независимых, достаточно общих атрибутов:
- Пользователь регистрируется в США;
- Его провайдер Privax LTD (оператор VPN);
- Email-Domain: [mail.ru, list.ru, bk.ru, inbox.ru].
Эти три атрибута, казалось бы, в отдельности ничего из себя не представляющие, вместе дают вероятность того, что это спамер, практически 90%.
Таких паттернов можно извлечь сколько угодно на каждый тип спамера. Это гораздо эффективнее и проще, чем просматривать вручную все аккаунты или даже кластеры.
Кластеризация текстов
Помимо кластеризации пользователей по атрибутам, можно находить пользователей, которые пишут одинаковые тексты. Конечно, это уже не так просто. Дело в том, что наш сервис работает на очень многих языках. Более того, пользователи часто пишут с сокращениями, на сленге, иногда с ошибками. Ну а сами сообщения обычно очень короткие, буквально 3–4 слова (примерно 25 символов).
Соответственно, если мы хотим находить похожие тексты среди миллиардов сообщений, которые пишут пользователи, нам нужно придумать что-то необычное. Если пытаться использовать классические методы на основе анализа морфологии и настоящего честного процессинга языка, то со всеми этими ограничениями, сленгами, сокращениями и кучей языков, это сделать очень сложно.
Можно поступить чуть более просто — применить алгоритм n-gram. Каждое сообщение, которое появляется, разбивается на n-граммы. Если n=2, то это биграммы (пары букв). Постепенно все сообщение разделяется на пары букв и собирается статистика, сколько раз каждая биграмма встречается в тексте.
На биграммах можно не останавливаться, а добавить триграммы, скипграммы (статистика по буквам через 1, 2 и т.д. букв). Чем больше мы получим информации, тем лучше. Но даже биграммы уже достаточно хорошо работают.
Дальше мы из биграмм каждого сообщения получаем вектор, длина которого равна квадрату длины алфавита.
С этим вектором очень удобно работать и его кластеризовать, потому что:
- состоит из чисел;
- сжатый, там нет пустот;
- всегда фиксированного размера.
- алгоритм k-means с такими сжатыми векторами фиксированного размера работает очень быстро. Наши миллиарды сообщений кластеризуются буквально за несколько минут.
Но это еще не все. К сожалению, если мы просто соберем все сообщения, которые похожи по частотности биграмм, то получим сообщения, которые похожи по частотности биграмм. При этом они не обязаны быть на самом деле хоть как-то похожи по смыслу. Часто встречаются длинные тексты, у которых векторы очень близки, практически совпадают, но сами тексты совершенно разные. Более того начиная с определенной длины текста этот метод кластеризации вообще перестанет работать, т.к. частоты биграмм сравняются.
Поэтому нужно добавить фильтрацию. Так как кластеры уже есть, они достаточно маленькие, мы легко можем внутри кластера сделать фильтрацию применив Stemming или Bag of Words. Внутри маленького кластера можно буквально все сообщения со всеми сравнить, и получить тот кластер, в котором гарантированно находятся одинаковые сообщения, которые совпадают не только по статистике, но и на самом деле.
Итак, мы сделали кластеризацию — и, тем не менее, для нас (и для кластеризации) очень важно знать правду о пользователе. Если он пытается от нас скрыть правду, то нам нужно предпринять какие-то действия.
Сокрытие информации
Типичный вид сокрытия информации — это VPN, TOR, Proxy, Анонимайзеры. Пользователь использует их, пытаясь сделать вид, что он из Америки, хотя на самом деле он из Нигерии.
Для того, чтобы победить эту проблему, мы взяли самый известный учебник «Как вычислить по IP».
С помощью этого учебника мы написали классификатор VPN — то есть такой классификатор, который получает на вход IP-адрес и на выходе говорит, является ли этот IP-адрес VPN, Proxy или нет.
Для реализации классификатора нам понадобится несколько ингредиентов:
- База данных ISP (Internet Service Provider), то есть соответствие IP-адресов всем существующим провайдерам. Такую базу можно приобрести, стоит она не очень дорого.
- Информация из Whois. По IP-адресу в Whois доступно много разной информации: страна; провайдер; подсеть, в которую входит IP-адрес; иногда то, что этот IP-адрес принадлежит хостингу и т.д. Можно проанализировать текст на конкретные слова и увидеть, что вообще из себя представляет IP-адрес.
- База GeolP. Если база нам говорит, что IP-адрес находится в Норвегии, а все пользователи, которые пользуются этим норвежским IP-адресом разбросаны по Африке, то, наверное, с этим IP-адресом что-то не так.
- Статистика пользователей — сколько пользователей нашего сервиса на этом IP-адресе заблокировано, сколько из них совпадает с данными GeolP, Whois, сколько не совпадает.
Взяв всю эту информацию, можно построить классификатор, который в итоге будет говорить, является ли IP-адрес VPN или нет.
Мы выбрали деревья решений, потому что они очень хорошо умеют находить те самые паттерны — конкретные сочетания провайдеров, стран, статистики и т.д., которые в итоге позволяют определить, что IP-адрес является VPN.
Конечно, эти данные очень общие. Как бы мы хорошо не обучали классификатор, как бы мы не старались применять advanced-техники, он все равно не будет работать со 100% точностью. Поэтому здесь ключевым фактором являются дополнительные сетевые проверки.
Как только мы получили информацию о том, что IP-адрес якобы принадлежит VPN, мы можем на самом деле проверить, что же этот IP-адрес из себя представляет. Можно попытаться к нему подключиться, посмотреть, какие на нем открыты порты. Если там SOCKS-proxy, можно попробовать открыть соединение и точно определить является данный IP-адрес анонимайзером или нет.
Кроме того, есть еще замечательная технология, внедрение которой у нас пока в планах, которая называется p0f. Это утилита, которая на сетевом уровне делает fingerprinting трафика и позволяет сразу определить, что находится на той стороне соединения: обычный пользовательский клиент, VPN-клиент, Proxy и т.д. Утилита содержит большой набор паттернов, которые все это определяют.
Наиболее подозрительное действие
После того, как мы написали различные системы, кластеризаторы, классификаторы, собрали статистику, мы задумались: что самого подозрительного пользователь может совершить на нашем сервисе? Зарегистрироваться — это уже подозрительно! Если пользователь зарегистрировался, то мы сразу начинаем на него смотреть с очень хитрым прищуром и всячески его анализировать, пытаясь понять, что же он имел ввиду.
У нас часто возникает внутреннее желание — а не забанить ли нам сразу всех после регистрации? Это бы значительно облегчило работу отдела Антиспама. Мы сразу сможем пить чай в 2 раза дольше, и никаких проблем у нас не будет.
Чтобы такие мысли пресекать не только у себя, но и у систем, которые мы пишем, и не банить всех хороших пользователей, особенно сразу после регистрации, мы вынуждены создавать системы, которые борются с другими нашими системами, то есть организуют сами себе ограничения.
Как можно себя ограничить, чтобы не банить хороших пользователей, не ошибиться и не запутаться?
«User Decency»
Классифицируем пользователей по честности — сделаем изолированную модель, которая будет брать все положительные характеристики пользователя и делать по ним анализ.
Пример характеристик «хорошего» поведения:
- длина диалогов;
- давность регистрации;
- отсутствие жалоб;
- пройденные верификации;
- покупки.
На наборе данных всех отдельных исключительно хороших характеристик пользователя можно обучить классификатор или регрессию. У нас работает простая логистическая регрессия. Эта модель легко портируется, поскольку представляет из себя просто набор коэффициентов, и ее легко реализовать в любой системе и на любом языке, она очень хорошо переносится между платформами и инфраструктурами.
Взяв пользователя и прогнав его через эту модель, мы получим коэффициент, который мы называем «коэффициентом честности». Если он равен нулю, то, как правило, это значит, что у нас почти нет информации об этом пользователе. Тогда никакой дополнительной информации мы из классификации не получаем.
Если коэффициент честности пользователя равен 1, то, скорее всего, пользователь представляет из себя хорошего парня, мы его трогать не будем — никаких верификаций и бана к нему не придет.
Такая изолированная штука позволяет нам предотвратить многие типичные ошибки.
False positive
Второе, что можно сделать — искать различные ложноположительные срабатывания. Бывает, что пользователи случайно заходят с одного IP-адреса. Например, двое сидят в интернет-кафе, даже компьютер может быть у них один и тот же. Браузер, fingerprint, который мы считаем по компьютеру, по браузеру, по устройству — все будет абсолютно совпадать, и мы можем посчитать, что оба пользователя являются спамерами, хотя не факт, что они как-то связаны.
Другой пример: хороший пользователь в диалоге со спамером может переспросить в ответ на рекламу: «Эй, я не понял — что такое Pornhub — зачем ты мне его рекламируешь?» В такой момент система видит, что пользователь написал стоп-слово и может посчитать, что этот пользователь является спамером и его нужно как можно скорее забанить.
Поэтому нам приходится заниматься поиском аномалий. Мы берем пользователей, их атрибуты, и ищем среди них тех пользователей, которые попали в плохую компанию совершенно случайно.
Для примера возьмем стоп-слово «Pornhub». По каждому стоп-слову у нас есть статистика всех пользователей, которые когда-либо его употребляли.
В какой-то момент новый пользователь Патрик употребляет то же самое стоп-слово, и мы должны добавить его в эту плохую компанию и забанить.
Здесь нужно проверить, отличается ли новый пользователь Патрик от всех старых, уже известных спамеров. Можно сравнить его типовые атрибуты: пол, возраст, провайдер, приложение, страна и т.д. Здесь нам важно понять, насколько велико «расстояние» в этом пространстве атрибутов между пользователем и основной группой. Если оно очень большое, то Патрик, скорее всего, попал туда случайно. Он ничего плохого не имел в виду, его не стоит сразу банить, а лучше отправить на ручную проверку.
Когда мы построили такую систему, у нас стало гораздо меньше случаться типовых ложноположительных срабатываний.
Универсальный мега-классификатор
Вы можете спросить — а почему бы не сделать сразу большую классную систему с MachineLearning, нейросетями и деревьями решений, которая будет получать на вход всю информацию о пользователях и выдавать просто 0 или 1 — человек спамер или нет.
Пытаясь создать одну универсальную модель, очень легко прийти к ситуации, когда перед нами окажется черный ящик, который сложно контролировать. В нем хорошее от плохого не отделено, система сама от себя никак не изолирована, и от ошибок защищена только ручной проверкой и косвенными метрикам. К тому же на большом объёме данных собрать всю информацию и статистику, чтобы подать мега-системе на вход, достаточно сложно.
Более того, все известные системы машинного обучения представляют собой не одну модель — это десяток моделей. Любой голосовой помощник или система распознавания лиц — это несколько моделей, соединенных в одну очень сложную систему.
В итоге нам стало понятно, что гораздо более правильным (с нашей точки зрения) является путь, когда создаются отдельные классификаторы и системы кластеризации, которые решают свою отдельную задачу. Идеально, чтобы, как в нашем случае, на каждый отдельный тип спама создавалась отдельная модель и отдельно же контролировалась различными способами: другими моделям, косвенными метриками, а также вручную. Только так можно будет надеяться избежать большинства ложных срабатываний.
Приходите на HighLoad++ 2018, в этом году будет много докладов по машинному обучению и искусственному интеллекту, например:
- Сергей Виноградов представит стандартизацию жизненного цикла ML-модели и покажет, как их эксплуатировать в продакшне без приключений
- Дмитрий Коробченко из NVIDIA расскажет об алгоритмических трюках, которые используются под капотом реальных боевых нейронных сетей.
- Артем Кондюков разберет интересный use case машинного обучения в фармацевтике.
Видео прошедших докладов собираем на youtube-канале, новости о будущих темах публикуем в рассылке — подписывайтесь, если хотите быть в курсе обо всем в мире высоких нагрузок.
- 39691 просмотр
Сейчас на сайте
Сейчас на сайте 0 пользователей и 15 гостей.
Copyright © Home Co. Ltd. LLC, 2008-2022 - Kurgan-Telecom.Ru - VDS/VPS Хостинг в Кургане - All Rights Reserved

