Asterisk + UniMRCP + VoiceNavigator. Синтез и распознавание речи в Asterisk
Учитывая, возросший интерес сообщества к Asterisk решил внести и свою лепту и рассказать о построении голосовых меню с использованием синтеза и распознавания речи.
Статья рассчитана на специалистов, имеющих опыт работы с построением IVR в Asterisk и имеющих представление о системах голосового самообслуживания.
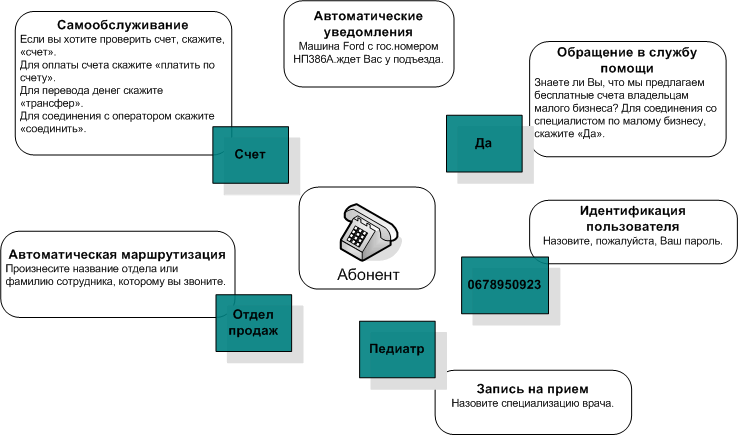
СГС (системы голосового самообслуживания) значительно расширяют возможности по созданию голосовых приложений и позволяют пользователю получать информацию и заказывать услуги самостоятельно, без участия оператора. Это может быть маршрутизация вызовов, запрос и выдача информации по расписанию авиарейсов, состояние банковского счета, заказ такси, запись на прием к врачу и пр.
Распознавание позволяет отказаться от линейных меню, создаваемых с помощью DTMF, разговаривать с системой человеческим языком и легко создавать меню с множественным выбором.
Синтез значительно упрощает работу с динамически меняющейся информацией и большими объемами текстовых данных.
Ниже я буду описывать интеграцию Asterisk с VoiceNavigator, т.к. являюсь сотрудником компании его разрабатывающей и занимаюсь, в том числе, поддержкой и интеграцией с малыми платформами (Asterisk, FreeSWITCH). Сразу скажу, что решение платное. Реально работающих OpenSource приложений для синтеза и распознавания русской речи нет.
Принятым в индустрии стандартом для реализации функционала синтеза и распознавания является использование протокола MRCP.
В Asterisk для этого используется библиотека UniMRCP.
UniMRCP – это кроссплатформенное ПО с открытым исходным кодом, включающее необходимые средства для реализации функций MRCP-клиента и MRCP-сервера.
Проект неспешно развивается и, насколько мне известно, это единственное на сегодня OpenSource решение для работы с MRCP-протоколом. Поддерживает Asterisk(все версии, начиная с 1.4) и FreeSWITCH.
VoiceNavigator является программным комплексом, который устанавливается на отдельную машину с Windows и предоставляет доступ к движкам синтеза и распознавания посредством протокола MRCP.
Включает в себя STC MRCP Server, комплекс синтеза речи STC TTS и комплекс распознавания речи STC ASR.
MRCP-сервер управляет взаимодействием между используемой голосовой платформой и модулями ASR и TTS. STC MRCP Server поддерживает следующие голосовые платформы: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP-запросы передаются командами протокола RTSP.
Для передачи звуковых данных используется протокол RTP.
Голосовая платформа через MRCP-сервер запрашивает доступ к модулям распознавания и синтеза речи, в зависимости от этого используются различные схемы взаимодействия.
Модуль ASR занимается распознаванием речи. Ключевым понятием для ASR является SRGS-грамматика.
SRGS (speech recognition grammar specification) – стандарт, который описывает структуру грамматики, используемой в распознавании речи. SRGS позволяет задавать слова или словосочетания, которые могут быть распознаны речевым движком.
Создание грамматик – это отдельная наука и при наличии интереса, готов написать отдельную статью.
Модуль TTS использует язык разметки SSML (Speech Synthesis Markup Language) основанный на XML для применения в приложениях синтеза речи.
Управление синтезом происходит с помощью тегов. С их помощью можно определить произношение, управлять интонацией, скоростью, громкостью, длиной пауз, правилами чтения и т.д.
Пример синтеза речи от ЦРТ можно послушать здесь vitalvoice.ru/demo
Звонок поступает на голосовую платформу.
Голосовая платформа активирует сценарий голосового меню, по которому происходит дальнейшее взаимодействие с абонентом.
Сценарий голосового меню определяет: когда система должна прочитать абоненту инструкцию, задать вопрос и как обработать его ответ.
VoiceNavigator принимает от голосовой платформы запросы на распознавание и синтез речи, выполняют их и возвращают результат выполнения по протоколу MRCP.
При распознавании речи, голосовая платформа передает SRGS-грамматику и оцифрованную речь и получает ответ в виде NLSML.
При синтезе речи, голосовая платформа передает plain-текст или SSML и получает в ответ синтезированную речь.
Перейдем к практической части.
Ниже описана установка UniMRCP на родную для Asterisk CentOS. При установке на другие ОС могут быть незначительные отличия.
Скачиваем с официального сайта последнюю версию uni-ast-package-0.3.2.
Пакет содержит:
• Asterisk версии 1.6.2.9 – работа с этой версией проверена разработчиком UniMRCP;
• Asterisk-UniMRCP-Bridge 0.1.0 – мост для сопряжения Asterisk и UniMRCP модуля;
• UniMRCP – Модуль UniMRCP 1.0.0;
• APR – Apache Portable Runtime 1.4.2;
• APR-Util – Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP – SIP User-Agent library 1.12.10.
Для установки требует autoconf, libtool, gcc, pkg-config.
После распаковки видим в корне папки три скрипта:
ast-install.sh – устанавливает идущий в поставке Asterisk, если он не установлен в системе.
uni-install.sh – устанавливает UniMRCP
connector-install.sh – устанавливает бридж между Asterisk и UniMRCP.
Запускаем их именно в таком порядке (если Asterisk установлен — ast-install.sh не надо) и отвечаем на все вопросы утвердительно.
Смотрим, чтобы все установилось без ошибок.
По моему опыту ошибки бывают только при неудовлетворении зависимостей. Если Asterisk ранее собирался из исходников, то все зависимости уже должны быть удовлетворены и установка пройдет легко и быстро.
После установки у Asterisk появилось 2 новых модуля res_speech_unimrcp.so и app_unimrcp.so, а диалплан обзавелся командами MRCPSynth и MRCPRecog. В корректности установки можно убедиться, введя в консоли Asterisk:
Прежде чем получить возможность работать с ресурсами синтеза и распознавания, необходимо подключить их. Для подключения к MRCP-серверу используется файл /etc/asterisk/mrcp.conf. Можно отредактировать его содержимое или заменить следующим (комментарии добавлены для пояснения наиболее важных параметров):
После перезапуска Asterisk профиль будет активирован и система готова к работе и созданию первого голосового приложения.
Как было описано ранее, Asterisk для работы использует функции MRCPSynth и MRCPRecog библиотеки app_unimrcp.so:

Функция MRCPSynth имеет следующий формат:
MRCPSynth(text, options), где
text — текст для синтеза (текст \ SSML),
options — параметры синтеза.
Параметры синтеза:
p — Профиль подключения к ресурсу синтеза, содержащийся в файле mrcp.conf
i — Цифры, по нажатию которых на телефоне, синтез будет прерван
f — Имя файла для записи синтезированной речи (запись производится в raw, запись не производится, если параметр или имя файла не заданы)
v — Голос, которым требуется осуществить синтез, например, «Мария8000».
plain-text:
SSML:
Преимуществом применения SSML по сравнению с plain-text является возможность использования различных тегов (голос, скорость и выразительность речи, паузы, интерпретация текста и т.д.).
Функция MRCPRecog имеет следующий формат:
MRCPRecog(grammar,options), где
grammar – грамматика (URL \ SRGS), задается ссылкой на файл, расположенный на http-сервере или непосредственно в теле функции.
options — параметры распознавания.
Параметры распознавания:
p — Профиль подключения к ресурсу распознавания, содержащийся в файле mrcp.conf
i — Цифры кода DTMF, при получении которых распознавание будет прервано.
При значении «any» или других символах, распознавание будет прерываться при их получении, а символ будет возвращаться в план набора.
f — Имя файла для проигрывания в качестве приглашения
b — Возможность прервать проигрываемый файл (режим barge-in) и начать распознавание (нельзя перебить=0, можно перебить и обнаружение речи осуществляет ASR движок=1, можно перебить и обнаружение речи осуществляет Asterisk=2)
t — Время, по истечении которого система распознавания может прервать процедуру распознавания с кодом recognition-timeout (003), в случае, если распознавание началось, и нет ни одного варианта распознавания. Значение задается в миллисекундах в диапазоне [0..MAXTIMEOUT].
ct — Порог уверенного распознавания (0.0 – 1.0).
Если confidence-level, возвращаемый при распознавании, меньше confidence-threshold, то результат распознавания no match.
sl — Чувствительность к несловарным командам. (0.0 — 1.0). Чем больше значение, тем выше чувствительность к шуму.
nb — Определяет количество возвращаемых результатов распознавания. Возвращается N результатов распознавания, с уровнем достоверности больше confidence-threshold. Значение по умолчанию = 1.
nit — Время, по истечении которого система распознавания может прервать процедуру распознавания, с кодом no-input-timeout (002), в случае, если распознавание началось и не найдено речи. Значение задается в миллисекундах, в диапазоне [0..MAXTIMEOUT].
Задание грамматики в теле функции:
Указание ссылки на грамматику:
Параметры f=hello&b=1 обеспечивают озвучивание звукового файла, например, «Произнести число от 1 до 100», который можно прервать с помощью barge-in, т.е. начать говорить, не дослушав сообщение до конца и тем самым запустить процесс распознавания.
Результат распознавания возвращается в Asterisk в виде NLSML в переменную ${RECOG_RESULT}.
Пример ответа:
Наиболее важными параметрами в данном выводе являются:
Результат распознавания = «восемь»
Confidence Level = 90
Семантический тег: 8
На начальном этапе логику приложения можно строить с использованием REGEX, например
Более правильным является использование парсера NLSML.
Парсер, который идет в комплекте с VoiceNavigator, является AGI-скриптом на Perl. Ему можно передать значение переменной exten => s,n,AGI(NLSML.agi,${QUOTE(${RECOG_RESULT})}) и в результате получить переменные ${RECOG_UTR0} = восемь, ${RECOG_INT0} = 8, ${RECOG_CNF0} = 90.
В следующей серии будет подробнее рассказано об используемых тегах синтеза и построении грамматик распознавания.
Статья рассчитана на специалистов, имеющих опыт работы с построением IVR в Asterisk и имеющих представление о системах голосового самообслуживания.
СГС (системы голосового самообслуживания) значительно расширяют возможности по созданию голосовых приложений и позволяют пользователю получать информацию и заказывать услуги самостоятельно, без участия оператора. Это может быть маршрутизация вызовов, запрос и выдача информации по расписанию авиарейсов, состояние банковского счета, заказ такси, запись на прием к врачу и пр.
Распознавание позволяет отказаться от линейных меню, создаваемых с помощью DTMF, разговаривать с системой человеческим языком и легко создавать меню с множественным выбором.
Синтез значительно упрощает работу с динамически меняющейся информацией и большими объемами текстовых данных.
Ниже я буду описывать интеграцию Asterisk с VoiceNavigator, т.к. являюсь сотрудником компании его разрабатывающей и занимаюсь, в том числе, поддержкой и интеграцией с малыми платформами (Asterisk, FreeSWITCH). Сразу скажу, что решение платное. Реально работающих OpenSource приложений для синтеза и распознавания русской речи нет.
Синтез и распознавание русской речи в Asterisk
Принятым в индустрии стандартом для реализации функционала синтеза и распознавания является использование протокола MRCP.
В Asterisk для этого используется библиотека UniMRCP.
UniMRCP – это кроссплатформенное ПО с открытым исходным кодом, включающее необходимые средства для реализации функций MRCP-клиента и MRCP-сервера.
Проект неспешно развивается и, насколько мне известно, это единственное на сегодня OpenSource решение для работы с MRCP-протоколом. Поддерживает Asterisk(все версии, начиная с 1.4) и FreeSWITCH.
VoiceNavigator
VoiceNavigator является программным комплексом, который устанавливается на отдельную машину с Windows и предоставляет доступ к движкам синтеза и распознавания посредством протокола MRCP.
Включает в себя STC MRCP Server, комплекс синтеза речи STC TTS и комплекс распознавания речи STC ASR.
MRCP-сервер
MRCP-сервер управляет взаимодействием между используемой голосовой платформой и модулями ASR и TTS. STC MRCP Server поддерживает следующие голосовые платформы: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP-запросы передаются командами протокола RTSP.
Для передачи звуковых данных используется протокол RTP.
Голосовая платформа через MRCP-сервер запрашивает доступ к модулям распознавания и синтеза речи, в зависимости от этого используются различные схемы взаимодействия.
ASR
Модуль ASR занимается распознаванием речи. Ключевым понятием для ASR является SRGS-грамматика.
SRGS (speech recognition grammar specification) – стандарт, который описывает структуру грамматики, используемой в распознавании речи. SRGS позволяет задавать слова или словосочетания, которые могут быть распознаны речевым движком.
Создание грамматик – это отдельная наука и при наличии интереса, готов написать отдельную статью.
TTS
Модуль TTS использует язык разметки SSML (Speech Synthesis Markup Language) основанный на XML для применения в приложениях синтеза речи.
Управление синтезом происходит с помощью тегов. С их помощью можно определить произношение, управлять интонацией, скоростью, громкостью, длиной пауз, правилами чтения и т.д.
Пример синтеза речи от ЦРТ можно послушать здесь vitalvoice.ru/demo
Схема работы
Звонок поступает на голосовую платформу.
Голосовая платформа активирует сценарий голосового меню, по которому происходит дальнейшее взаимодействие с абонентом.
Сценарий голосового меню определяет: когда система должна прочитать абоненту инструкцию, задать вопрос и как обработать его ответ.
VoiceNavigator принимает от голосовой платформы запросы на распознавание и синтез речи, выполняют их и возвращают результат выполнения по протоколу MRCP.
При распознавании речи, голосовая платформа передает SRGS-грамматику и оцифрованную речь и получает ответ в виде NLSML.
При синтезе речи, голосовая платформа передает plain-текст или SSML и получает в ответ синтезированную речь.
Установка и настройка UniMRCP
Перейдем к практической части.
Ниже описана установка UniMRCP на родную для Asterisk CentOS. При установке на другие ОС могут быть незначительные отличия.
Скачиваем с официального сайта последнюю версию uni-ast-package-0.3.2.
Пакет содержит:
• Asterisk версии 1.6.2.9 – работа с этой версией проверена разработчиком UniMRCP;
• Asterisk-UniMRCP-Bridge 0.1.0 – мост для сопряжения Asterisk и UniMRCP модуля;
• UniMRCP – Модуль UniMRCP 1.0.0;
• APR – Apache Portable Runtime 1.4.2;
• APR-Util – Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP – SIP User-Agent library 1.12.10.
Для установки требует autoconf, libtool, gcc, pkg-config.
После распаковки видим в корне папки три скрипта:
ast-install.sh – устанавливает идущий в поставке Asterisk, если он не установлен в системе.
uni-install.sh – устанавливает UniMRCP
connector-install.sh – устанавливает бридж между Asterisk и UniMRCP.
Запускаем их именно в таком порядке (если Asterisk установлен — ast-install.sh не надо) и отвечаем на все вопросы утвердительно.
Смотрим, чтобы все установилось без ошибок.
По моему опыту ошибки бывают только при неудовлетворении зависимостей. Если Asterisk ранее собирался из исходников, то все зависимости уже должны быть удовлетворены и установка пройдет легко и быстро.
После установки у Asterisk появилось 2 новых модуля res_speech_unimrcp.so и app_unimrcp.so, а диалплан обзавелся командами MRCPSynth и MRCPRecog. В корректности установки можно убедиться, введя в консоли Asterisk:
*CLI> module show like mrcp
Module Description Use Count
res_speech_unimrcp.so UniMRCP Speech Engine 0
app_unimrcp.so MRCP suite of applications 0
2 modules loadedПрежде чем получить возможность работать с ресурсами синтеза и распознавания, необходимо подключить их. Для подключения к MRCP-серверу используется файл /etc/asterisk/mrcp.conf. Можно отредактировать его содержимое или заменить следующим (комментарии добавлены для пояснения наиболее важных параметров):
[general]
;Профили для ASR и TTS, используемые по умолчанию.
;Возможна работа одновременно с несколькими MRCP-серверами
default-asr-profile = vn-internal
default-tts-profile = vn-internal
; UniMRCP logging level to appear in Asterisk logs. Options are:
; EMERGENCY|ALERT|CRITICAL|ERROR|WARNING|NOTICE|INFO|DEBUG -->
log-level = DEBUG
max-connection-count = 100
offer-new-connection = 1
; rx-buffer-size = 1024
; tx-buffer-size = 1024
; request-timeout = 60
;Имя профиля
[vn-internal]
; +++ MRCP settings +++
;Версия MRCP-протокола
version = 1
;
; +++ RTSP +++
; === RSTP settings ===
; Адрес MRCP-сервера
server-ip = 192.168.2.106
;Порт, по которому VoiceNavigator принимает запросы на синтез и распознавание
server-port = 8000
; force-destination = 1
;Расположение ресурсов синтеза и распознавания на MRCP-сервере
;(для VoiceNavigator – пустое значение)
resource-location =
;Имена ресурсов синтеза и распознавания в VoiceNavigator
speechsynth = tts
speechrecog = asr
;
; +++ RTP +++
; === RTP factory ===
;IP-адрес компьютера, на котором установлен Asterisk и с которого будет сниматься RTP-трафик.
rtp-ip = 192.168.2.104
; rtp-ext-ip = auto
;Диапазон RTP-портов
rtp-port-min = 32768
rtp-port-max = 32888
; === RTP settings ===
; --- Jitter buffer settings ---
playout-delay = 50
; min-playout-delay = 20
max-playout-delay = 200
; --- RTP settings ---
ptime = 20
codecs = PCMU PCMA L16/96/8000
; --- RTCP settings ---
rtcp = 1
rtcp-bye = 2
rtcp-tx-interval = 5000
rtcp-rx-resolution = 1000После перезапуска Asterisk профиль будет активирован и система готова к работе и созданию первого голосового приложения.
Как было описано ранее, Asterisk для работы использует функции MRCPSynth и MRCPRecog библиотеки app_unimrcp.so:
MRCPSynth
Функция MRCPSynth имеет следующий формат:
MRCPSynth(text, options), где
text — текст для синтеза (текст \ SSML),
options — параметры синтеза.
Параметры синтеза:
p — Профиль подключения к ресурсу синтеза, содержащийся в файле mrcp.conf
i — Цифры, по нажатию которых на телефоне, синтез будет прерван
f — Имя файла для записи синтезированной речи (запись производится в raw, запись не производится, если параметр или имя файла не заданы)
v — Голос, которым требуется осуществить синтез, например, «Мария8000».
Пример использования функции в диалплане
plain-text:
exten => 7577,n,MRCPSynth(Произнесите имя и фамилию сотрудника)
SSML:
exten => 7577,MRCPSynth(<?xml version=\"1.0\"?><speak version=\"1.0\" xml:lang=\"ru-ru\" xmlns=\"http://www.w3.org/2001/10/synthesis\"><voice name=\"Мария8000\">Произнесите имя и фамилию сотрудника.</voice></speak>)
Преимуществом применения SSML по сравнению с plain-text является возможность использования различных тегов (голос, скорость и выразительность речи, паузы, интерпретация текста и т.д.).
MRCPRecog
Функция MRCPRecog имеет следующий формат:
MRCPRecog(grammar,options), где
grammar – грамматика (URL \ SRGS), задается ссылкой на файл, расположенный на http-сервере или непосредственно в теле функции.
options — параметры распознавания.
Параметры распознавания:
p — Профиль подключения к ресурсу распознавания, содержащийся в файле mrcp.conf
i — Цифры кода DTMF, при получении которых распознавание будет прервано.
При значении «any» или других символах, распознавание будет прерываться при их получении, а символ будет возвращаться в план набора.
f — Имя файла для проигрывания в качестве приглашения
b — Возможность прервать проигрываемый файл (режим barge-in) и начать распознавание (нельзя перебить=0, можно перебить и обнаружение речи осуществляет ASR движок=1, можно перебить и обнаружение речи осуществляет Asterisk=2)
t — Время, по истечении которого система распознавания может прервать процедуру распознавания с кодом recognition-timeout (003), в случае, если распознавание началось, и нет ни одного варианта распознавания. Значение задается в миллисекундах в диапазоне [0..MAXTIMEOUT].
ct — Порог уверенного распознавания (0.0 – 1.0).
Если confidence-level, возвращаемый при распознавании, меньше confidence-threshold, то результат распознавания no match.
sl — Чувствительность к несловарным командам. (0.0 — 1.0). Чем больше значение, тем выше чувствительность к шуму.
nb — Определяет количество возвращаемых результатов распознавания. Возвращается N результатов распознавания, с уровнем достоверности больше confidence-threshold. Значение по умолчанию = 1.
nit — Время, по истечении которого система распознавания может прервать процедуру распознавания, с кодом no-input-timeout (002), в случае, если распознавание началось и не найдено речи. Значение задается в миллисекундах, в диапазоне [0..MAXTIMEOUT].
Пример использования функции в диалплане
Задание грамматики в теле функции:
exten => 7577,n,MRCPRecog(<?xml version=\"1.0\"?><grammar xmlns=\"http://www.w3.org/2001/06/grammar\" xml:lang=\"ru-ru\" version=\"1.0\" mode=\"voice\" root=\"test\"><rule id=\"test\"><one-of><item>один</item><item>два</item><item>три</item><item>четыре</item><item>пять</item><item>шесть</item><item>семь</item><item>восемь</item><item>девять</item></one-of></rule></grammar>,f=hello&b=1)
Указание ссылки на грамматику:
exten => 7577,n,MRCPRecog(http://192.168.1.1/digits.xml,f=hello&b=1)
Параметры f=hello&b=1 обеспечивают озвучивание звукового файла, например, «Произнести число от 1 до 100», который можно прервать с помощью barge-in, т.е. начать говорить, не дослушав сообщение до конца и тем самым запустить процесс распознавания.
Результат распознавания возвращается в Asterisk в виде NLSML в переменную ${RECOG_RESULT}.
Пример ответа:
<?xml version="1.0"?><result grammar="C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf"><interpretation confidence="90" grammar="C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf"><input mode="speech" confidence="90" timestamp-start="2011-07-04T0-00-00" timestamp-stop="2011-07-04T0-00-00">восемь</input><instance confidence="90"><SWI_literal>восемь</SWI_literal><SWI_grammarName>C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf</SWI_grammarName><SWI_meaning>8</SWI_meaning></instance></interpretation></result>
Наиболее важными параметрами в данном выводе являются:
Результат распознавания = «восемь»
Confidence Level = 90
Семантический тег: 8
На начальном этапе логику приложения можно строить с использованием REGEX, например
exten => 8800,5,GotoIf(${REGEX("восемь" ${RECOG_RESULT})}?100:10)Более правильным является использование парсера NLSML.
Парсер, который идет в комплекте с VoiceNavigator, является AGI-скриптом на Perl. Ему можно передать значение переменной exten => s,n,AGI(NLSML.agi,${QUOTE(${RECOG_RESULT})}) и в результате получить переменные ${RECOG_UTR0} = восемь, ${RECOG_INT0} = 8, ${RECOG_CNF0} = 90.
Пример простого голосового приложения для распознавания чисел
exten => 7577,1,Answer
exten => 7577,n,MRCPSynth(Назовите число от одного до трех. Говорите после сигнала)
exten => 7577,n,MRCPRecog(<?xml version=\"1.0\"?><grammar xmlns=\"http://www.w3.org/2001/06/grammar\" xml:lang=\"ru-ru\" version=\"1.0\" mode=\"voice\" root=\"test\"><rule id=\"test\"><one-of><item>один</item><item>два</item><item>три</item></one-of></rule></grammar>,f=beep&b=1)
exten => 7577,n,GotoIf(${REGEX("один" ${RECOG_RESULT})}?one:if_2)
exten => 7577,n(if_2),GotoIf(${REGEX("два" ${RECOG_RESULT})}?two:if_3)
exten => 7577,n(if_3),GotoIf(${REGEX("три" ${RECOG_RESULT})}?three:error)
exten => 7577,n(one),MRCPSynth(Вы назвали число один)
exten => 7577,n,Hangup
exten => 7577,n(two),MRCPSynth(Вы назвали число два)
exten => 7577,n,Hangup
exten => 7577,n(three),MRCPSynth(Вы назвали число три)
exten => 7577,n,Hangup
exten => 7577,n(error),MRCPSynth(Извините не удалось распознать речь)
exten => 7577,n,HangupВ следующей серии будет подробнее рассказано об используемых тегах синтеза и построении грамматик распознавания.
- 33144 просмотра
Сейчас на сайте
Сейчас на сайте 0 пользователей и 0 гостей.
Copyright © Home Co. Ltd. LLC, 2008-2022 - Kurgan-Telecom.Ru - VDS/VPS Хостинг в Кургане - All Rights Reserved

